
C 언어 배우기
업데이트:
-
C 언어를 배워보자
-
이 글은 공부를 하며 완성중이다.
1. C 파일 실행 과정
-
- Preprocessing(전처리)
- 편집된 코드를 preprocessor에 전달한다. 이때 #으로 시작하는 directive(지시어)의 지시를 따르게 된다.
-
- Compiling
- Preprocessing을 끝마친 프로그램을 compiler에 전달한다. Comiler는 Source code를 기계어 명령문(Machine code, Object code)로 번역한다. 즉 C, C++, Python, R 등의 문법에 따라 사람이 작성한 Source code를 컴퓨터가 이해할 수 있도록 0과 1로 구성된 2진법으로 변환한다. 컴파일링 결과 object file 즉 *.obj 파일을 생성한다.
- gcc와 clang이 컴파일러다.
-
- Linking
- linker가 compiling으로 생성된 object code를 프로그램을 실행하기 위한 추가적인 코드(라이브러리 내부의 명령문, 예컨대 printf 등)과 결합해 실행파일(*.exe)를 만든다.
2. 기본 구조
<directives>
int main(void)
{
<statements>
}
2.1. 들여쓰기
Indentation style, 코드를 표기하는 스타일을 뜻한다. 어떤 방식을 사용해도 괜찮으나, 일관성을 지키며 사용하도록 하자. 이 글에선 K&R style을 기본으로 사용한다. 그러나, Allman style도 혼재되어 있을 수 있다. 필자는 K&R 스타일을 선호하나, Allman 스타일을 강요받고 있는데서 오는 습관에 의해서다. 참고자료
-
- K&R style
- Kernighan와 Ritchie의 책 ‘The C Programming Language’에서 활용한 방식
int main(void)
{
if (<condition>) {
<statements>;
}
}
-
- Allman style
- BSD Unix를 작성한 Eric Allman의 이름을 딴 방식
int main(void)
{
if (<condition>)
{
<statements>;
}
}
-
- Whitesmiths style
- 첫번째 상용 C compiler인 Whitesmiths Compiler에서 활용한 방식
int main(void)
{
if (<condition>)
{
<statements>;
}
}
-
- GNU style
- GNU 프로젝트에서 활용한 방식
int main(void)
{
if (<condition>)
{
<statements>;
}
}
2.1. Directive(지시어)
#로 시작하며, 파일에 포함할 것을 선언한다.
-
#include <header>- header 파일을 포함하는 문법
2.2. Header(헤더)
표준 라이브러리에 대한 정보를 담고 있는 파일이다. 즉 C 언어 개발자가 자주 사용하는 명령어를 미리 만들어서 모아둔 파일을 의미한다. 다른 언어와 다르게 C언어에는 내장 함수가 없기 때문에 표준 라이브러리에서 필요한 부분을 가져와야 한다. Python에서 함수, 변수, 클래스 등을 모아놓은 Module을 import하는 과정이라고 생각하면 된다. 단지 차이라면 print와 같은 기본 함수도 내장되지 않았다는 점이다.
2.2.1. Header list
-
- <stdio.h>
- standard input output header(표준 입출력 헤더)의 약자로, C언어의 표준 입출력 라이브러리에 대한 정보를 담고 있다.
- printf(): print formatted
- scanf(): scan formatted
- getchar(): 문자를 입력받는다.
- putchar(): 문자를 출력한다.
-
- <limits.h>
- 정수형 변수의 범위를 출력한다. limits.h
-
- <stdint.h>
- 크기를 정의한 정수 자료형 헤더 파일, 32bit, 64bit 등 CPU에 따라 달라지는 정수 자료형의 한계를 극복하기 위해 C99표준부터 추가됐다.
- int8_t, int16_t, int32_t, int64_t, uint8_t uint16_t, uint32_t, uint64_t…
-
- <float.h>
- 양의 실수 자료형의 최솟값과 최댓값이 정의된 헤더 파일
- FLT_MIN, FLT_MAX, DBL_MIN, DBL_MAX, LDBL_MIN, LDBL_MAX, FLT_EPSILON, DBL_EPSILON, LDBL_EPSILON …
-
- <time.h>
- time(시간)
-
- <ctype.h>
- toupper - 소문자인지 판별 후 소문자면 대문자로 변환
-
- <stdlib.h>
- standard library의 약자로, 문자열 변환, 난수 생성, 동적 메모리 관리 등이 정의된 헤더 파일
- atoi, atol, atof, strtol, strtoul, strtod, rand, srand, malloc, calloc, realloc, free, abort, exit, atexit…
- stdlib.h_1 stdlib.h_2 stdlib.h_3
-
<string.h>
-
- strlen()
- String length(문자열 길이)
- size_t strlen(const char *s)
-
- strcmp()
- String compare(문자열 비교)
- int strcmp(const char *s1, const char *s2)
-
- strcpy()
- String copy(문자열 복사)
- char *strcpy(char * dst, const char * src);
-
- strcat()
- String concatenate(문자열 붙이기)
- char *strcat(char *restrict s1, const char *restrict s2);
-
- sprintf()
- 문자열 서식을 지정하여 만든 문자열을 변수에 저장한다.
- int sprintf(char * restrict str, const char * restrict format, …);
sprinft(s1, "Hello, %s", "world!");
#include <stdio.h> #include <string.h> #include <stdlib.h> int main(void) { char* s1 = malloc(sizeof(char) * 31); sprintf(s1, "pi = %.2f", 3.14); printf("%s\n", s1); free (s1); return (0); }
-
- strchr()
- String character, 찾을 문자를 문자열의 왼쪽에서 오른쪽으로 검색
- char *strchr(const char *s, int c)
-
- strrchr()
- string (find from the right) character), 찾을 문자를 문자열의 오른쪽에서 왼쪽으로 검색
- char *strrchr(const char *s, int c)
-
- strstr()
- string (find) string, 찾을 문자열을 문자열의 왼쪽에서 오른쪽으로 검색
- char *strstr(const char *haystack, const char *needle);
-
2.3. Function(함수)
함수는 사용자가 만든 함수와 C에서 제공하는 함수(Library function)으로 나뉜다. 동시에 함수는 결괏값을 반환하는 함수와 결괏값이 없는 함수로 구분된다.
-
main- C언어에서 프로그램이 동작할 영역을 나타내는 함수로 필수적으로 1개 만 존재해야 한다. 만약 main 함수가 2개라면 error가 발생한다. main 함수는 프로그램이 종료될 때 운영체제에 status code(상태코드)를 반환한다.
2.4. Statement(구문)
프로그램 작동 시 실행되는 명령의 집합으로 각 statement는 반드시 ;(semicolon)으로 끝내야 한다. 참고로 directive와 compound statement(복합문)에는 ;이 필요 없다. 그러나 소수의 예외적인 경우를 제외하고 ;를 반드시 붙여 구문이 끝나는 지점을 표시해야 한다.
자 이제 Hello, world!를 출력하는 코드를 분석해보자.
#include <stdio.h>
int main(void)
{
printf("Hello, world!\n");
return 0;
}
이 코드의 의미는 다음과 같다.
printf 함수를 포함한 stdio.h 헤더를 불러와서 ‘Hello, world!’와 프로그램 실행 결괏값을 반환하겠다.
-
#include <stdio.h>: ‘stdio.h’ 헤더 파일을 호출한다. -
int: integer의 약자로 정수를 의미한다. -
int main(): 메인 함수는 정수형이다. -
void: 함수의 입력값을 요구하지 않겠다. -
{: main 함수 영역의 시작 지점. -
printf("Hello, world!\n"):: ()안의 내용 ‘Hello, world!’를 출력한다.-
\n: 개행문자(new-line character)라고 불리며, enter와 동일한 기능을 수행한다. -
return 0;: 함수의 결괏값을 반환한다. 즉 이 함수에서는 정수값 0을 반환한다. 0은 정상적인 종료를 의미하며, 1은 오류가 발생했음을 의미한다. -
}: main 함수의 영역의 종료 지점.
실행 결과는 다음과 같다.
Hello, world!
Program ended with exit code: 0
3. 기본 문법
3.1. 주석(comment)
주석은 compiler가 처리하지 않기 때문에 프로그램에 영향을 주지는 않지만, 사용자의 이해를 돕기 위해 사용한다. 작성자 외 타인이 코드를 볼 때 참고할 수 있고, 작성자 본인도 코드가 많아질수록 모든 코드를 기억할 수 없기 때문에 간단한 설명을 덧붙이는 것이 좋다.
/* */와 // 두 가지 방법 중 선택해서 사용할 수 있다. /* */방식은 여러 줄을 포함할 수 있는 반면 //는 한 줄에만 적용 된다는 차이점이 존재한다. 참고로 /* */는 시인성을 위해 다양한 방법을 사용할 수 있다. 아래 예시를 참고하자.
- e.g.
// 주석입니다.
// comment area
/* 주석입니다. */
/* comment area */
/* 주석입니다.
comment area
*/
/*******
* 주석입니다.
* comment area
********/
/*
* 주석입니다.
* comment area
*/
3.2. Format specifier(서식지정자)
%[flags][width][.precision][length]specifier
변수를 활용해 출력할 때 사용한다.
참고자료 1
참고자료 2
참고자료 3
3.2.1. flags
| flags | Description |
|---|---|
\- |
왼쪽 정렬 |
+ |
부호를 출력한다.(양수면 +, 음수면 -) |
|
Space(공백), 음수일때만 부호를 출력한다.(양수일 때는 공백) |
# |
8진법과 16진법인 경우(%o, %x, %X) 각각 0, 0x, 0X를 접두사로 추가한다. |
0 |
출력하는 width의 남는 공간을 0으로 채운다. |
3.2.2. width
부호, 정수부분, 소수점, 실수부분을 합한 너비를 지정한다. 즉 출력할 글자의 최소 개수를 지정한다. 실제 값이 지정한 너비보다 넓다면 실제 값을 출력한다.
*를 사용해서 (“%*, <width>, value)의 형태로도 표현할 수 있다.
- e.g.1
#include <stdio.h>
int main(void)
{
int num = 999;
printf("%9d\n", num);
return 0;
}
999
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
float num = 3.14F;
printf("%0*.9f\n", 15, num);
return 0;
}
0003.140000105
Program ended with exit code: 0
3.2.3. .percision(정밀도)
소수점 자리 수를 설정한다.
*를 사용해서 (“%.*”, <.percision>, value)의 형태로도 표현할 수 있다.
- e.g.1
#include <stdio.h>
int main(void)
{
float num = -3.14F;
printf("%+015.9f\n", num);
return 0;
}
-0003.140000105
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
float num = 3.14F;
printf("%+0*.*f\n", 30, 20, num);
return 0;
}
+00000003.14000010490417480469
Program ended with exit code: 0
3.2.4. length
정수형의 경우 long을 의미하는 l와 long long을 의미하는 ll, short를 의미하는 h, char를 의미하는 hh는 d, u, o, x 앞에 붙어 의미를 확장시킬 수 있다.
실수형의 경우 long double 값은 e, f, g 앞에 L(대문자 L)을 붙여줘야 한다.
| size | Description |
|---|---|
hh |
char, %hhd, %hhu, %hho, %hhx |
h |
short, %hd, %hu, %ho, %hx |
l |
long, %ld, %lu, %lo, %lx |
ll |
long long, %lld, %llu, %llo, %llx |
L |
long double, %Le, %LE, %Lf, %Lg, %LG |
3.2.5. type
| size | Description |
|---|---|
%c |
Character(문자) |
%s |
string of chracters(문자열) |
%d or %i |
decimal(10진수), char, short, int |
%ld or %li |
long decimal(integer), long |
%lld or %lli |
long decimal, long long |
%u |
usigned Decimal, char unsigned, short unsigned, int unsigned |
%lu |
long usigned Decimal, long unsigned |
%llu |
long long usigned Decimal, long long unsigned |
%f |
Floating point(부동소수점), float, double |
%lf |
double, C99부터 지원한다. |
%Lf |
Long float, long double |
%e |
exponential notation(지수 표기법), 소문자 사용(e) e.g. 1,230,000,000 = 1.23e+9 |
%Le |
Long exponential notation |
%E |
Exponential notation(지수 표기법), 대문자 사용(E) > e.g. 0.000000123 = 1.23E7 |
%g |
%f와 %e 중 짧은 것 자동으로 사용 |
%G |
%F와 %E 중 짧은 것자동으로 사용 |
a |
실수를 16진법으로 변환(소문자) |
A |
실수를 16진법으로 변환(대문자) |
%o |
Octal(8진법) |
%x |
Hexadecimal(16진법), 소문자 사용(0123456789abcdef) |
%X |
Hexadecimal(16진법), 대문자 사용(0123456789ABCDEF) |
%% |
% |
%p |
Pointer |
%lf가 C99부터 추가된 이유는 이전에는 scanf에서 double을 %lf로 표현했으나, printf에서는 %lf를 지원하지 않아 혼동이 발생했기 때문이다. 참고로 printf에서 %f와 %lf는 동일한 기능을 수행한다. 그러나 이전 표준과의 호환을 위해 printf에서 %lf의 사용을 자제하는 것이 좋다.
printf가 %f로 double과 float을 활용할 수 있는 반면 scanf에서 double과 float의 서식지정자를 구분하는 이유는 Default argument promotions 때문이다.
다음은 모두 같은 결과를 출력한다.
- e.g.
printf("Hello, world!\n");
printf("%s\n", "Hello, world!");
printf("%s, %s!\n", "Hello", "world");
Hello, world!
3.3. 접미사(Suffix)
literal을 사용할 때 접미사를 활용해 크기를 지정한다.
- Int literal suffix
Suffix Data type int l, L long u, U unsigned int ul, UL unsigned long ll, LL long long ull, ULL unsigned long long - Float literal suffix
Suffix Data type f, F float double l, L long double - e.g.
#include <stdio.h>
int main(void)
{
printf("%d\n", 123);
printf("%ld\n", 123L);
printf("%lu\n", 123UL);
printf("%lld\n", 123LL);
printf("%llu\n", 123ULL);
printf("%f\n", 123.0F);
printf("%f\n", 123.0);
printf("%Lf\n", 123.0L);
return 0;
}
123
123
123
123
123
123.000000
123.000000
123.000000
Program ended with exit code: 0
3.4. Escape sequence(확장 비트열)
| Escape sequence | Description |
|---|---|
| \n | Enter |
| \t | Tab |
3.5. Define(정의)
# define <MACRO>
상수를 포함할 때는 상수 값에 대한 정의를 하는 것이 좋다. 또한 정의할 때는 대문자만을 사용하는 것이 암묵적인 규칙이므로 이를 따르는 것이 협업을 할 때 좋다.
- e.g.
#include <stdio.h>
#define PI 3.141592F
int main(void)
{
float _r;
float area;
printf("원의 반지름을 입력하세요: ");
scanf("%f", &_r);
area = _r * _r * PI;
printf("원의 넓이는 %f입니다.\n", area);
}
원의 반지름을 입력하세요: 9.9
원의 넓이는 307.907410입니다.
Program ended with exit code: 0
3.6. Default argument promotions
Variable argument를 사용하거나 Prototype이 없는 함수에 적용된다.
char, short를 int로 Type promotion(형 확장)
float을 double로 Type promotion(형 확장)
참고자료1
참고자료2
참고자료3
참고자료4
참고자료5
참고자료6
-
- Function Prototype
- 함수 이름(Function’s name)과 Prameters 및 return type을 main 함수 전에 선언하는 것. 단, function body는 생략한다.
-
- 아래 예제에서 function prototype
-
- return type은 int
- Prototype이 필요한 이유는 컴파일러가 순차적으로 소스 코드를 해석하기 때문이다. 즉 main 함수에서 정의된 적 없는 함수를 사용할 경우 컴파일러는 해당 함수에 대한 정보를 가지고 있지 않기 때문에 컴파일 오류를 발생시킨다. 이러한 오류를 방지하기 위해 main 함수 전에 main 함수에서 사용할 함수가 소스 코드 내에 존재한다는 것을 알려주는 용도로 prototype을 선언한다. 따라서 main 함수보다 먼저 main 함수에서 사용할 함수를 선언하는 경우 prototype 없이도 원활히 컴파일된다.
- 참고자료
-
- Variable argument(가변 인수)
- printf, scanf에서 Parameter(매개변수)의 개수가 정해져 있지 않아, argument의 개수가 유동적인 것.
-
- 可(허락할 가)變(변할 변), 성질이나 모양이 달라질 수 있음. <-> 불변
-
- Parameter(매개변수)
- 함수를 선언할 때 사용하는 변수
-
- 아래 예제에서 int sum(int a, int b)에서 a와 b가 Parmeter이다.
-
- Argument(인수)
- 함수 내부에서 함수의 값을 결정하는 변수
-
- 아래 예제에서 10과 20이 Argument이다.
-
- 引(넘겨줄 인) 數(셈 수), 인자라고도 한다.
- 정의
- e.g.
#include <stdio.h>
int sum(int a, int b); // function prototype
// int sum(int, int); 로 표현 가능.
int main(void)
{
int res = sum(10, 20); // function call
printf("%d\n", res);
return 0;
}
int sum (int a, int b) // function definition
{
result = a + b; // function body
return result; // return statement
}
4. 변수(Variable)
<자료형> <변수명>;
변수는 사용 전 반드시 선언(Declare)해야 한다. 즉 변수의 형(type)를 정하고 사용할 변수 명을 선언해야 한다. 선언하고 난 뒤 변수에 값을 할당(Assignment)할 수 있다. 처음 변수에 값을 할당할 때는 ‘변수를 초기화(initialization)한다’고 표현한다.
변수는 바뀔 수 있는 값을 보관하는 저장소다. 예컨대 $y = 3x + 2$ 에서 $x$와 $y$가 변수이다.
변수는 가급적 최상단에 선언하는 것이 좋다. 구형 Compiler에서는 중간에 변수를 선언할 경우 ERROR가 발생할 수 있다.
- e.g.
#include <stdio.h>
int main(void)
{
/*
변수는 선언과 할당을 동시에 할 수도 있고 따로 할 수도 있으며,
선언과 초기화도 동시에 가능하다.
*/
int x, y, a = 3;
int b = 2;
x = 10;
y = a * x + b;
printf("y = %dx + %d\n", a, b);
printf("if x is %d, y = %d\n", x, y);
return 0;
}
y = 3x + 2
if x is 10, y = 32
Program ended with exit code: 0
- 규칙
- 변수명은 숫자로 시작할 수 없다. 시작은 _(Underscore)와 문자만 가능하다.
- 대문자, 숫자, _(Underscore)만 변수명에 사용 가능하다.
- 변수명은 띄어쓰기할 수 없다.
- int, short, long, float, for 등 C언어의 키워드1는 사용할 수 없다.
- 변수 사용 전에 변수를 선언해야 한다. 위에서부터 아래로 작동하기 때문에 선언하지 않은 변수가 나오면 Error가 발생한다.
5. 자료형(Data type)
자료형을 구분해서 사용하는 이유는 자료형에 따라 사용하는 메모리가 달라지기 때문이다. 예컨대 100을 char로 표현하면 1byte만 사용하면 되지만, long long으로 표현하게 되면 8bytes를 사용하게 된다. 즉 7bytes에 달하는 불피요한 메모리를 사용하게 되는 것이다. 따라서 적절한 자료형을 찾아 활용해야 한다.
5.1. 2진법(Binary)
100을 다양한 방식으로 표현해보자. \(64_{16} = 100_{10} = 144_{8} = 1100100_{2}\)이다. 그렇다면 0.1은 2진법으로 어떻게 표현할까? $0001100110011…_{2}$이다. 즉 0011이 계속 반복된다. 따라서 2진법으로 소수를 정확하게 표현할 수 없고, 근사치를 사용할 수 밖에 없다.
실수를 2진법으로 표현하게 되면 대부분 정확한 값이 아니라 근사값임을 명심하자.
- 100을 2진법으로 변환
n $a_{n}$ $a_{n} \div 2 (a_{0} = 100)$ Remainder(나머지)
$a_{n} \% 2$0 100 50 0 1 50 25 0 2 25 12 1 3 12 6 0 4 6 3 0 5 3 1 1 6 1 0 1
- 0.1을 2진법으로 변환
n 자리수 $a_{n-1} \times 2 (a_0 = 0.1)$ $a_n$ $x=$
$a_n <1 \rightarrow 0$
$a_n < 1 \sim 1$$y=2^{-n}$ $x \times y$ 1 -1 0.1 * 2 0.2 0 0.5 0 2 -2 0.2 * 2 0.4 0 0.25 0 3 -3 0.4 * 2 0.8 0 0.125 0 4 -4 0.8 * 2 1.6 1 0.0625 0.0625 5 -5 0.6 * 2 1.2 1 0.03125 0.03125 6 -6 0.2 * 2 0.4 0 0.015625 0 7 -7 0.4 * 2 0.8 0 0.0078125 0 8 -8 0.8 * 2 1.6 1 0.00390625 0.00390625 9 -9 0.6 * 2 1.2 1 0.001953125 0.001953125 10 -10 0.2 * 2 0.4 0 0.0009765625 0 11 -11 0.4 * 2 0.8 0 0.00048828125 0 12 -12 0.8 * 2 1.6 1 0.000244140625 0.000244140625 13 -13 0.6 * 2 1.2 1 0.0001220703125 0.0001220703125 … … … … SUM 0.0999755859375
5.1.1. Two’s complement(2의 보수)
음수를 표현할 때 각 자리의 숫자를 반전하고(0 -> 1, 1 -> 0) 1을 더한다.
예를들어 1byte일 때 127은 0 111 1111이다.
따라서 -127은 0 111 1111을 반전한 1 000 0000에서,
1을 더해 1 000 0001로 표현한다.
참고자료
| Decimal value | Two’s-complement Representation(1byte) |
|---|---|
| 127 | 0 111 1111 |
| 126 | 0 111 1110 |
| 125 | 0 111 1101 |
| 124 | 0 111 1100 |
| … | … |
| 4 | 0 000 0010 |
| 3 | 0 000 0100 |
| 2 | 0 000 0011 |
| 1 | 0 000 0001 |
| 0 | 0 000 0000 |
| -1 | 1 111 1111 |
| -2 | 1 111 1110 |
| -3 | 1 111 1101 |
| -4 | 1 111 1100 |
| … | … |
| -126 | 1 000 0010 |
| -127 | 1 000 0001 |
| -128 | 1 000 0000 |
8비트로 표현할 수 있는 정수 범위는 -128 ~ 127이다. 이를 이진법으로 표현하면 1 000 0000 ~ 0 111 1111이다. 이 때 음수값을 표현하는것을 주목하자. 음수 중 가장 큰 값은 -1이다. 즉 0 111 1111로 0을 표현한다. 반대로 가장 작은 값은 1 000 0000으로 표현하고 이는 -128과 대응된다.
5.1.2. Overflow와 Underflow
자료형의 범위를 넘어서면 overflow 또는 underflow가 발생한다.
Two’s complement를 상기하며 int 범위를 살펴보자. int의 범위는 1 000 0000 0000 000 0000 0000 0000 0000 ~ 0 111 1111 1111 1111 1111 1111 1111 1111이다.
Overflow는 최대값에서 +1이 될 때부터 발생한다. 만약 최대값에서 +1을 하면 1 000 0000 0000 000 0000 0000 0000 0000이 출력된다. 이러한 프로세스 때문에 양수에서 음수로 변하게 된다. 반대로 최소값에 -1을 하면 0 111 1111 1111 1111 1111 1111 1111 1111이 되어 underflow가 발생한다.
-
- Buffer overflow
- 허용된 메모리를 초과하는 데이터를 할당할 때 발생하는 오류
- e.g.
#include <stdio.h>
int main(void)
{
char a = 128;
char b = -129;
printf("a is %d\nb is %d\n", a, b);
return 0;
}
a is -128
b is 127
Program ended with exit code: 0
5.1.3. 고정소수점(Fixed point)
정수를 표현하는 bit와 소수를 표현하는 bit를 고정해서 숫자를 표현하는 방식이다.
4bytes의 실수를 고정소수점으로 표현한다고 가정하자.
부호를 표시하기 위해 1bit를 사용하고 정수에 15bit, 실수에 16bit를 사용한다. 그런데 15bit는 0~32,767의 범위만 표현할 수 있다. 그리고 16bit는 1~0.0000152587890625까지만 표현할 수 있다. 즉 표현할 수 있는 범위가 매우 제한적이다.
| 부호(+=0, -=1) | 정수부 | 실수부 |
|---|---|---|
| 1bit | 15bit | 16bit |
100.1을 4bytes 고정소수점으로 표현해보자.
| + | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | -1 | -2 | -3 | -4 | -5 | -6 | -7 | -8 | -9 | -10 | -11 | -12 | -13 | -14 | -15 | -16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
다시 100.1을 2bytes 고정소수점으로 표현해보자. 정수부는 7bit, 실수부는 8bit다.
| + | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | -1 | -2 | -3 | -4 | -5 | -6 | -7 | -8 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
2bytes의 고정소수점으로 표현할 수 있는 양의 값 중 최대값과 최솟값을 구해보자.
- Max 값은 255.99609375이다.
+ 7 6 5 4 3 2 1 0 -1 -2 -3 -4 -5 -6 -7 -8 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 - Min 값은 0.00390625이다.
+ 7 6 5 4 3 2 1 0 -1 -2 -3 -4 -5 -6 -7 -8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
5.1.4. 부동소수점(Floating point)
일반적으로 IEEE 754 표준 부동소수점 계산 방식을 활용한다.
부동소수점의 정규화 표현식은 아래와 같다.
\(Sign \quad\) \(Significand(Mantissa, fraction)\) \(\times Base(Radix)^{Exponent}\)
\(\qquad 부호 \quad 가수 \times 기수^{지수}\)
아래 예시를 확인하면 부동소수점을 정규화하는 과정에서 소수점이 이동한다. 즉 소수점이 물 위를 떠다니듯 움직인다고 하여 붙여진 이름이다. 참고로 부동은 한자로 浮動으로 뜰 부에 움직일 동으로, 不(아닐 부)가 아니다.
| Type | Sign | Exponent | Significand field | Total bits | Exponent bias | Bits precision | Number of decimal digits | E min | E max |
|---|---|---|---|---|---|---|---|---|---|
| Single | 1 | 8 | 23 | 32 | 127 | 24 | ~7.2 | -126 | +127 |
| Double | 1 | 11 | 52 | 64 | 1,023 | 53 | ~15.9 | -1,022 | +1,023 |
| Quad | 1 | 15 | 112 | 128 | 16,383 | 113 | ~34.0 | -16,382 | +16,383 |
Exponent(지수)는 8bit가 할당되어 0~255까지 총 $2^{8}$(256)개의 숫자를 표현할 수 있다. 그런데 0000 0000은 Signed Zero를, 1111 1111은 Infinite(무한대)를 표현하기로 약속(예약)했다. 따라서 남은 254개(0000 0001 ~ 1111 1110)으로 숫자를 표현해야 한다. 그런데 음수를 표현하기 위해 값을 할당하면 1bit가 낭비된다.
따라서 Exponent bias를 더해 예시
Signed Zero = 0000 0000,
-126 = 0000 0001,
0 = 0111 1111,
127 = 1111 1110,
INF = 1111 1111로 표현한다.
그렇다면 왜 -127 ~ +126이 아니라 -126 ~ +127일까? 예상컨대 \(2^{126}\)과 \(2^{127}\)은 매우 큰 차이가 나지만, \(2^{-127}\)과 \(2^{-126}\)은 큰 차이가 나지 않기 때문인 것으로 추측한다. \(\lim\limits_{n\to\infty}{2^{-n}}\)이 0임을 상기할 때 0에 가까운 수는 차이가 미미하다. 따라서 +127로 더 큰 값을 포함할 수 있도록 설계한 것으로 예상한다.
IEEE-754의 Single-Precision에서 Normalized number 중 가장 작은 수는 0 \(\;\) 0000 0001 \(\;\) 000 0000 0000 0000 0000 0000이다. hidden bit를 더해 다시 표현해보면 1.000 0000 0000 0000 0000 0000\(E^{-126}\)이다. 이를 다시 풀면 0.000…0001 (.(point)와 1사이의 0은 총 126개)이고 따라서 \(+1 \times 2^{-126}\) 즉 1.17549E-38이 된다. WolframAlpha
그런데 1.17549E-38이 32bit를 사용해서 표현할 수 있는 제일 작은 수일까? 아니다. 1.0을 0.0으로 만들면 0.000 0000 0000 0000 0000 0001을 만들 수 있다. 그런데 정규 표현식에 해당하지는 않는다. 그리고 정규 표현식에 해당하지 않는 표현을 Denormalized number이라고 한다.
가장 작은 Denormalized number는 0 \(\;\) 0000 0000 \(\;\) 000 0000 0000 0000 0000 0001이다. 그리고 그 값은 \(+ 1 \times 2^{-149}\), 1.4013E-45이다. 참고로 149는 126과 Significand field의 23을 더한 값으로 .(point)를 이동해보면 알 수 있다.
주의해야 할 점은 Significand가 모두 0일 수는 없다. 모두 0이라면 Signed Zero와 구분되지 않기 때문이다. 또한 Exponent가 0000 0001이 아닌 이유는 Normalized number와 구분하기 위함이다. 따라서 Exponent가 0000 0000이고 Significand가 0이 아니면 Denormalized number에 해당한다.
정규화(Normalized)는 실수를 정규화 표현식(\(n.xxx 2^{m}\))으로 변환하는 과정을 의미한다. 예시
참고자료1
참고자료2
참고자료3
참고자료4
참고자료5
참고자료6
참고자료7
참고자료8
참고자료9
- Signed Zero
- 음수 0과 양수 0을 구분해서
- Negative Zero(-0) = 1 $\;$ 0000 0000 $\;$ 000 0000 0000 0000 0000 0000
- Positive Zero(+0) = 0 $\;$ 0000 0000 $\;$ 000 0000 0000 0000 0000 0000
single 자료형은 32bit 단정도(Single-Precision)을 의미하며,
double 자료형은 64bit 배정도(Double-Precision)을 의미한다.
Exponent bias는 지수(Exponent)가 음수가 되는 것을 방지하기 위해 사용한다.
100.5를 2진법으로 표현해보자.
정수부분 100은 \(1100100_{2}\)고 소수부분 0.5는 \(1_{2}\)로 \(1100100.1_{2}\)이다.
이를 정규화(Normalized)하면 Normalized Value는 \(1.1001001 \times 2^6\)이다.
정규화된 부동소수점을 32bit Single-Precision 형식으로 나타내면 0 $\;$ 1000 0101 $\;$ 100 1001 0000 0000 0000 0000이다. WolframAlpha
sign = + = 0,
exponent = 127 + 6 = 133 = 10000101,
significand = 1001001
이 때 significand가 11001001이 아님에 주목하자. 정규화를 하게 되면 significand의 첫번째 숫자는 항상 1임을 알 수 있다. 따라서 bit 1개를 더 사용하기 위해 정규화된 표현 식에서 변하지 않는 1을 hidden bit로 처리한다. 다시 말해 어떤 2진법 숫자라도 맨 앞자리 숫자는 1로 시작하므로 저장공간을 아끼기 위해 1을 생략해서 표현하는 것이다.
-0.375를 정규화해보자.
정수부분은 0이고 소수부분은 \(011_{2}\)로 \(0.011_{2}\)이다.
이를 정규화하면 \(1.1 \times 2^{-2}\)이다.
다시 정규화된 부동소수점을 32bit Single-Precision 형식으로 나타내면 1 $\;$ 0111 1101 $\;$ 100 0000 0000 0000 0000 0000이다. WolframAlpha
sign = - = 1,
exponet = 127 - 2 = 125 = 1111101,
significand = 1
위의 예시는 exponent가 음수인 경우다. 만약 exponent bias가 없었다면 exponent는 -2여야 한다. 따라서 - 부호를 표시하기 위해 exponent에 할당된 8bit 중 1bit를 할당해야 한다. 즉 저장공간 손실이 발생한다. 따라서 8bit exponent 하에서 지수의 최소값인 -127을 \(00000000_{2}\)로 표현하기 위해 bias를 127 더해주는 것이다. 따라서 최대값인 127은 \(11111111_{2}\)로 \(255_{10}\)로 표현된다
5.2. 정수(Integer)
정수 자료형은 ‘int’를 기반으로 signed, unsigned, short, long을 붙여 변수의 특성을 정의한다. 일반적으로 signed는 생략한다.
| Name | Size | Range |
|---|---|---|
| short(short int) | 2bytes(16bits) | -32,768 ~ 32,767 |
| short unsigned(short int unsigned) | 2bytes(16bits) | 0 ~ 65,535 |
| int | 4bytes(32bits) | -2,147,483,648 ~ 2,147,483,647 |
| unsigned int | 4bytes(32bits) | 0 ~ 4,294,967,295 |
| long(long int)[32bit] | 4bytes(32bits) | -2,147,483,648 ~ 2,147,483,647 |
| long unsigned(long int unsigned)[32bit] | 4bytes(32bits) | 0 ~ 4,294,967,295 |
| long(long int)[64bit] | 8bytes(32bits) | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| long unsigned(long int unsigned)[64bit] | 8bytes(32bits) | 0 ~ 18,446,744,073,709,551,615 |
| long long(long long int) | 8bytes(64bits) | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| long long unsigned(long long int unsigned) | 8bytes(64bits) | 0 ~ 18,446,744,073,709,551,615 |
-
- signed
- 양수와 음수를 포함한 정수를 표현한다.
-
- unsigned
- 부호가 없는 정수를 표현한다. 즉 0부터 자연수의 범위를 표현한다.
-
- Integer
- -9, 0, 10… 소수점이 없는 숫자(정수)를 의미한다. int는 메모리 공간을 4bytes(32bits) 사용한다.
-
- Decimal
- 10진수, 0 ~ 9를 사용해 표기하는 일반적인 숫자 표현 방식이다.
-
- Octal
- 8진수, 0 ~ 7을 사용해 표기하며 0으로 시작한다.
- \(100_{8}\) = 0144
-
- Hexadecimal
- 16진수, 0 ~ 9, a ~ f를 사용해 표기하며 0x로 시작한다.
- \(100_{10}\) = 0x64
signed와 int는 생략하는 것이 가독성 측면에서 좋다.
long/short, int, signend/unsigned의 순서는 상관없다. 그러나 정규표현식의 순서가 헷갈리지 않게 long/short + int + unsigend 순서로 기억하자.
후술하겠지만 32 bit와 64bit compiler에 따라 자료형의 범위가 달라지는 것을 기억하자.
5.2.1. 정수형 크기
sizeof(<expression> or <type>);
sizeof() 함수를 활용해 도출할 수 있다.
- e.g.
#include <stdio.h>
int main(void
{
printf("%s is %dbyte\n", "char", sizeof(char));
printf("%s is %dbytes\n", "short", sizeof(short));
printf("%s is %dbytes\n", "int", sizeof(int));
printf("%s is %dbytes\n", "long", sizeof(long));
printf("%s is %dbytes\n", "long long", sizeof(long long));
return 0;
}
char is 1byte
short is 2bytes
int is 4bytes
long is 8bytes
long long is 8bytes
Program ended with exit code: 0
5.2.2. 정수형 범위
표준 라이브러리에서 limits.h 헤더를 활용해 자료형 범위를 도출할 수 있다.
- e.g.
#include <stdio.h>
#include <limits.h>
int main(void)
{
printf("char range is %d ~ %d\n", CHAR_MIN, CHAR_MAX);
printf("short range is %d ~ %d\n", SHRT_MIN, SHRT_MAX);
printf("int range is %d ~ %d\n", INT_MIN, INT_MAX);
printf("long range is %ld ~ %ld\n", LONG_MIN, LONG_MAX);
printf("long long range is %lld ~ %lld\n", LLONG_MIN, LLONG_MAX);
return 0;
}
char range is -128 ~ 127
short range is -32768 ~ 32767
int range is -2147483648 ~ 2147483647
long range is -9223372036854775808 ~ 9223372036854775807
long long range is -9223372036854775808 ~ 9223372036854775807
Program ended with exit code: 0
대다수의 문헌에서 long int의 range를 $2^{32}$으로 표현한다. 그러나 연산 결과는 $2^{64}$였다. 결괏값이 다른 이유는 32bit 컴파일러와 64bit compiler의 차이로 발생한다. 즉 32bit 운영체제에서는 long을 4bytes로 취급하나, 64bit 운영체제에서는 long을 8byte로 취급한다. 따라서 사용하는 OS와 compiler에 따라 자료형 크기가 바뀐다. 이러한 현상이 발생하는 이유는 C99 표준에서 각 자료형의 최소값 만을 정해놓았기 때문이다.
즉 char는 1byte 이상,
short는 2bytes 이상,
int는 CPU 레지스터(Processor Register) 크기(cpu가 가장 효율적으로 연산할 수 있는 크기)를 참고하고 최소 2bytes 이상,
long은 int보다 크거나 같으면서 4bytes 이상,
longlong은 8bytes 이상으로 정의되어 있다.
Mac OS는 LP64 Data model을 사용한다. 그렇기 때문에 맥은 64bit 운영 체제를 사용함에도 int는 32bit, long과 pointer는 64bit를 기본 크기로 사용한다.
참고로 Processor는 CPU를 의미하며 Register는 data를 일시적으로 저장하는 공간이다.
참고자료 1
참고자료 2
참고자료 3
참고자료 4
참고자료 5
- Size and alignment of base data types in OS X(LP64)
Data type LP64 size LP64 alignment char 1 byte 1 byte short 2 bytes 2 bytes int 4 bytes 4 bytes long 8 bytes 8 bytes pointer 8 bytes 8 bytes size_t 8 bytes 8 bytes long long 8 bytes 8 bytes fpos_t 8 bytes 8 bytes off_t 8 bytes 8 bytes
LP64의 의미는 Long과 Pointer가 64bits라는 의미다. 참고로 ILP64는 Int, Long, Pointer가 64bits를 의미하며, LLP64는 LongLong과 Pointer가 64bits임을 의미한다.
참고로 1bit는 1과 0을 표현할 수 있고, 1byte는 8bit로 구성된다. 따라서 2bit로 표현할 수 있는 수는 \(00_2\), \(01_2\), \(10_2\), \(11_2\) 총 4가지 정수로 순서대로 0, 1, 2, 3을 의미한다. 따라서 4bytes이면 \(2^{32}-1\)의 숫자까지 표현이 가능하다. 그러나 signed 즉 양수와 음수가 존재하게 되면 표현 범위는 반으로 줄어든다. 즉 음수는 \(-\frac{2^n+1}{2}\), 양수는 \(\frac{2^n -1}{2}\) 까지 표현할 수 있다.
- 등비수열의 합 공식 증명
\(\begin{align} S_n &= ar^0 + ar^1 + ar^2 ... + ar^{n-1} \\ r \times S_n &= \, \, \, \qquad ar^1 + ar^2 ... + ar^{n-1} + ar^n \\ \\ rS_{n} - S_{n} &= (r-1)S_n = ar^n -a \\ \therefore S_n &= \frac{a(r^n-1)}{r-1} \\ \end{align}\) \(\begin{align} \therefore if \quad a = 1, r = 2 \rightarrow then \sum_{n=0}^{n-1}{2^n} = 2^n -1 \end{align}\)
다르게 설명하면 4bytes의 최소값은 0000 0000 0000 0000이고, 최대값은 1111 1111 1111 1111이다. 그런데 부호를 포함하게 되면 맨 앞의 bit에 sign을 할당해야 한다. 즉 최소값은 1 000 0000 0000이고 최대값은 0 111 1111 1111 1111이다.
5.3. 실수형
f와 l로 실수형을 따로 지정해주지 않으면 기본적으로 double로 연산한다. The C Programming Language에서 관련 논의가 존재한다.
실수 자료형은 underflow가 발생하면 0으로 처리하고, overflow가 발생하면 inf(infinity)가 출력된다.
| Name | Size | Range | Literal |
|---|---|---|---|
| float | 4bytes(32bits) | 1.175494e-38 ~ 3.402823e+38 | f or F |
| double | 8bytes(64bits) | 2.225074e-308 ~ 1.797693e+308 | |
| long double | 16bytes(128bits) | 3.362103e-4932 ~ 1.189731e+4932 | L or L |
실수를 할당할 때 F(f)나 L(l)을 붙여주지 않으면 모든 실수를 double로 인식한다. 즉 long double은 double로 인식하게 되면서 8bytes가 잘리게 된다. float은 f를 안 붙여도 동일한 결과를 출력하는 것으로 보인다. 그러나 double 보다 데이터 활용에 이점이 있기 때문에 f를 붙이는 것으로 추측된다. 일반적으로 float num_f = 3.14의 경우 “warning C4305: ‘초기화 중” : ‘double’에서 ‘float’으로 잘립니다.”라는 경고2가 뜬다는데 xcode에서는 동일한 결괏값을 출력해서 확인할 수 없다.
- e.g.
#include <stdio.h>
int main(void)
{
float num_F = 3.14F;
float num_f = 3.14;
double num_d = 3.14;
long double num_Ld = 3.5E-400L;
long double num_ld = 3.5E-400;
printf("num_F is %.40f\n", num_F);
printf("num_f is %.40f\n", num_f);
printf("num_d is %.40f\n", num_d);
printf("num_Lf is %.Le\n", num_Ld);
printf("num_lf is %.Le\n", num_ld);
return 0;
}
num_F is 3.1400001049041748046875000000000000000000
num_f is 3.1400001049041748046875000000000000000000
num_d is 3.1400000000000001243449787580175325274467
num_Lf is 4e-400
num_lf is 0e+00
Program ended with exit code: 0
num_lf의 경우 아래와 같은 경고가 발생한다.
“Magnitude of floating-point constant too small for type ‘double’; minimum is 4.9406564584124654E-324”
5.3.1. 실수형 크기
sizeof(<expression> or <type>);
sizeof() 함수를 활용해 도출할 수 있다.
- e.g.
#include <stdio.h>
int main(void)
{
printf("%s size is %d\n", "float", sizeof(float));
printf("%s size is %d\n", "double", sizeof(double));
printf("%s size is %d\n", "long double", sizeof(long double));
return 0;
}
float size is 4
double size is 8
long double size is 16
Program ended with exit code: 0
5.3.2. 실수형 범위
표준 라이브러리에서 float.h 헤더를 활용해 자료형 범위를 도출할 수 있다.
- e.g.
#include <stdio.h>
#include <float.h>
int main(void)
{
printf("float range is %.10f ~ %.1f\n", FLT_MIN, FLT_MAX);
printf("double range is %.10f ~ %f\n", DBL_MIN, DBL_MAX);
printf("long double range is %.10Lf ~ %Lf\n", LDBL_MIN, LDBL_MAX);
printf("float range is %e ~ %e\n", FLT_MIN, FLT_MAX);
printf("double range is %e ~ %e\n", DBL_MIN, DBL_MAX);
printf("long double range is %Le ~ %Le\n", LDBL_MIN, LDBL_MAX);
return 0;
}
float range is 0.0000000000 ~ 340282346638528859811704183484516925440.0
*/ double과 longdouble은 숫자가 너무 커서 생략 /*
float range is 1.175494e-38 ~ 3.402823e+38
double range is 2.225074e-308 ~ 1.797693e+308
long double range is 3.362103e-4932 ~ 1.189731e+4932
Program ended with exit code: 0
overflow와 underflow 만들어보기
- e.g.
#include <stdio.h>
#include <float.h>
int main(void)
{
printf("FLT_MAX is %G\n", FLT_MAX);
printf("FLT_MAX * 2 is %G\n", FLT_MAX * 2);
printf("-FLT_MAX is %G\n", -FLT_MAX);
printf("-FLT_MAX * 2 is %G\n", -FLT_MAX * 2);
printf("FLT_MIN is %G\n", FLT_MIN);
printf("FLT_MIN / 10000000.0F is %G\n", FLT_MIN / 10000000.0F);
printf("FLT_MIN / 100000000.0F is %G\n", FLT_MIN / 100000000.0F);
printf("FLT_TRUE_MIN is %G\n", FLT_TRUE_MIN);
printf("FLT_TRUN_MIN / 2 is %G\n", FLT_TRUE_MIN / 2);
}
FLT_MAX is 3.40282E+38
FLT_MAX * 2 is INF
-FLT_MAX is -3.40282E+38
-FLT_MAX * 2 is -INF
FLT_MIN is 1.17549E-38
FLT_MIN / 10000000.0F is 1.4013E-45
FLT_MIN / 100000000.0F is 0
FLT_TRUE_MIN is 1.4013E-45
FLT_TRUN_MIN / 2 is 0
Program ended with exit code: 0
출력값을 보면 FLT_MIN의 값이 float의 최소값이 아님을 알 수 있다. 이는 DBL_MIN과 LDBL_MIN도 마찬가지다.
_TURE_MIN은 ANSI C11부터 지원한다.
참고자료
5.4. 문자(Character)
char <variable> = <character>;
char에 문자를 저장하게 되면 아스키(ASCII)코드에 해당하는 정수값을 저장한다. 주의할 점은 char 문자는 말 그대로 문자 하나를 할당할 수 있다. 특히 작은 따옴표(‘‘)를 사용하는 것에 유의하자. char c1 = a는 c1에 a라는 변수를 할당하는 것이다. 그러나 a 변수는 선언된 적이 없기 때문에 이상한 값이 출력된다.
문자형 변수에 정수를 할당할 때는 unsigned인지 signend인지 구분해야 한다.
ASCII Code
| Name | Size | Range |
|---|---|---|
| char | 1byte(8bits) | -128 ~ 127 |
| char unsigned | 1byte(8bits) | 0 ~ 255 |
- e.g.
#include <stdio.h>
#include <float.h>
int main(void)
{
char c1 = "a";
char c2 = 'a';
char c3 = 'z';
char c4 = 122;
char c5 = 0x7a;
char c6 = 0;
char c7 = '0';
printf("ASCII code %c is %d(0x%x)\n", c1, c1, c1);
printf("ASCII code %c is %d(0x%x)\n", c2, c2, c2);
printf("ASCII code %c is %d(0x%x)\n", c3, c3, c3);
printf("ASCII code %c is %d(0x%x)\n", c4, c4, c4);
printf("ASCII code %c is %d(0x%x)\n", c5, c5, c5);
printf("ASCII code %c is %d(0x%x)\n", c6, c6, c6);
printf("ASCII code %c is %d(0x%x)\n", c7, c7, c7);
printf("%c + 1 = %c = %d(0x%x)\n", c2, c2 + 1, c2 + 1, c2 + 1);
return 0;
}
ASCII code \222 is -110(0xffffff92)
ASCII code a is 97(0x61)
ASCII code z is 122(0x7a)
ASCII code z is 122(0x7a)
ASCII code z is 122(0x7a)
ASCII code � is 0(0x0)
ASCII code 0 is 48(0x30)
a + 1 = b = 98(0x62)
Program ended with exit code: 0
c6과 c7를 통해 0과 ‘0’이 다른 것을 알 수 있다. 0은 ASCII code에서 NULL(Space)를 의미하고 ‘0’은 문자 0을 의미한다. 다시 말해 ASCII code에 대응되는 숫자를 입력하는 것과 문자를 입력하는 것의 차이로 인한 결과이다.
5.4.1. 문자열(String)
문자열은 ASCII NUL로 끝나는 연속된 문자의 집합이다. 그러나 모든 문자의 배열이 문자열은 아니다. 문자의 배열에 ASCII NUL이 포함되지 않은 경우 문자열이라고 할 수 없다. 따라서 문자열에는 반드시 ASCII NUL을 포함할 수 있는 충분한 메모리 크기를 할당해야 한다. 문자열의 길이에 ASCII NUL은 포함하지 않는다. C에서는 문자열을 저장하는 자료형이 존재하지 않고, char는 1개의 문자만 저장할 수 있다. 따라서
- 문자열 상수(literal)로 선언(큰 따옴표로 감싼 문자열)하거나,
char str = "abcd"; - 포인터에 문자열(값)을 저장하는 상수형 문자열 포인터를 사용하거나,
char* str; - 배열을 사용해 문자열을 출력할 수 있다.
char str[] = {a, b, c, d}; - 이때 문자열 포인터는 상수(const char*)이기 때문에 값을 변경할 수 없다. 반면 배열을 활용해 문자열을 선언하면 변수로 취급할 수 있기 때문에 배열로 문자열을 출력하는 것을 권장한다.
-
- Byte String
- char 데이터 타입의 배열(Sequence)
- string.h 파일에 정의되어 있다.
-
- Wide String
- wchar_t 데이터 타입의 배열(Sequence)
- wchar.h 파일에 정의되어 있다.
- 16bits or 32bits 크기를 가지며 비라틴(non-latin) 계열 문자 집합을 지원하기 위해 만들어졌다.
C언어는 문자열을 저장하는 자료형은 존재하지 않는다. 문자열을 사용할 수 있도록 하는 방법은 모두 문자열을 가리키는 포인터를 선언해 해결하는 방식이다.
NULL과 NUL은 다르다. NULL은 NULL Pointer를 의미하며, 일반적으로 ((void*)0)으로 정의한다. NUL은 ASCILL 문자로 ‘\0’으로 정의한다.
배열에 문자열 리터열을 할당하는 경우 반드시 선언과 동시에 문자열로 초기화해야 한다. 만약 선언한 후 다른 행에서 배열에 문자열을 초기화하면 오류가 발생한다.
문자열은 왼쪽을 앞(forward), 오른쪽을 뒤(backward)라고 부른다. 그러나 주소를 다루는 포인터 연산에서는 낮은 주소(0x0000000000000000)가 뒤(backward), 높은 주소(0xFFFFFFFFFFFFFFFF)가 앞(forward)이다. 그리고 포인터 연산에서 낮은 주소값으로 이동하는 것을 역방향(backward)로 이동한다고 표현하며, 높은 주소값으로 이동하는 것을 순방향(forward)으로 이동한다고 표현한다.
- e.g.1 배열을 사용한 문자열
#include <stdio.h>
int main(void)
{
char str[] = "Hello World!";
printf("%s\n", str);
printf("sizeof(str) = %d\n", sizeof(str));
return 0;
}
Hello World!
sizeof(str) = 13
Program ended with exit code: 0
str배열의 크기가 13임에 주목하자. “Hello World!”는 총 12글자다. 그러나 끝에 ASCII NUL이 포함되어 있기 때문에 크기가 13인 것이다. 만약 문자열 배열을 크기를 지정해서 선언할 때 반드시 ASCII NUL까지 고려해야 한다.
- e.g.2
#include <stdio.h>
int main(void)
{
char *str = "Hello";
char arr[] = "Hello";
char arr[] = {'H', 'e', 'l', 'l', 'o', '\0'};
char Arr_2[] = {'H', 'e', 'l', 'l', 'o'};
printf("str | %s, world!\n", str);
printf("arr | %s, world!\n", arr);
printf("Arr | %s, world!\n", Arr);
printf("Arr_2 | %s, world!\n", Arr_2);
printf("Arr pointer = %p\n", &Arr);
printf("Arr_2 pointer = %p\n", Arr_2);
arr[1] = 'i', arr[2] = 0;
printf("arr[4] = %c\n", arr[4]);
printf("arr | %s, world!\n", arr);
}
str | Hello, world!
arr | Hello, world!
Arr | Hello, world!
Arr_2 | HelloHello, world!
Arr pointer = 0x7ffeefbff4dc
Arr_2 pointer = 0x7ffeefbff4d7
arr[4] = o
arr | Hi, world!
Program ended with exit code: 0
이때 arr[1]과 arr[2]만 바꿨고, arr[4]값이 존재함에도 arr 값이 arr[0]과 arr[1]까지만 출력되는 이유는 무엇일까? ASCII코드에서 0은 nul을 의미하고 NUL문자는 문자열 끝에 추가되어 문자열이 끝나는 지점을 알려준다. 즉 arr[2]가 NUL 문자이기 때문에 arr의 문자열이 arr[1]까지 존재한다고 인식하는 것이다.
한편, NUL문자가 없는 Arr_2는 HelloHello가 출력된다. Arr_2 배열은 문자열의 끝을 모르기 때문에 NUL문자가 존재할 때까지 값을 출력하는 것이다. 위의 예시에서 Arr_2의 주소는 ~d7에서 ~db까지고, Arr은 ~dc에서 e1까지다. 따라서 Arr_2는 ~e1의 NUL문자일 때까지 값을 출력하고 그 결과고 Arr의 값까지 출력하는 것이다.
따라서 문자열을 배열로 복사할 때는 배열의 사이즈는 문자열 크기 + 1 이상이 필요하다. 사이즈가 선언된 배열에서도 NUL이 사용되는 이유 배열의 크기보다 작을 때 실제 문자열이 저장된 부분까지 출력하기 위함이다.
참고자료
&Arr도 pointer 값을 출력하고 Arr_2도 pointer 값을 출력하는 것을 주목하자. 두 가지 방법이 가능한 이유는 배열의 이름 자체가 pointer를 의미하기 때문이다. 즉 배열의 이름은 그 배열이 시작하는 주소값을 나타낸다.
- e.g.3 printf에서 큰따옴표(“ “)를 사용해 문자열 출력하기
#include <stdio.h>
int main(void)
{
printf("%cello, %s!\n", 'H', "world");
return 0;
}
Hello, world!
Program ended with exit code: 0
5.4.1. String Literal
literal 문자열은 literal 문자열을 구성하는 문자 배열을 저장하는 String Literal Pool에 할당된다. 일반적으로 대부분의 컴파일러에서 문자열 literal을 상수(읽기 전용)으로 취급한다. 따라서 literal을 바꾸려고 할 경우 segmentation fault가 발생한다. 그러나 GCC같은 소수의 컴파일러에서는 문자열 literal을 바꿀 수 있다. 따라서 const 처리를 통해 모든 컴파일러에서 동일한 결괏값이 출력되도록 하는 것이 바람직하다.
- e.g.1
#include <stdio.h>
int main(void)
{
printf("%p\n", "Affect");
char* str = "Affect";
printf("%s\n", str);
*(str + 0) = 'E';
return 0;
}
0x100003fa6
Affect
exited, segmentation fault
literal 문자열 “Affect”는 메모리 주소값을 반환한다. 따라서 배열에 문자열 리터럴을 할당할 수 없다.
char str[];
str = "affect";
- e.g.2 literal 문자열 바꾸기
malloc 활용해 포인터 변수를 선언하고, strcpy를 활용해 literal을 포인터에 초기화하는 방식으로 literal 문자열을 수정하게 할 수 있다. malloc은 뒤에 나오는 내용이므로 이런게 있다 정도만 알아두고 넘어가자.
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int main(void)
{
char* str1 = "Affect";
char* str2 = (char*)malloc(sizeof(char) * (strlen("Affect") + 1));
strcpy(str2, "Affect");
printf("str1 = %s\n", str1);
printf("str2 = %s\n", str1);
// *(str1 + 0) = 'E';
*(str2 + 0) = 'E';
printf("str2 = %s\n", str2);
free(str2);
return 0;
}
str1 = Affect
str2 = Affect
str2 = Effect
Program ended with exit code: 0
5.5. 논리 자료형(Boolean)
TRUE(참)과 FALSE(거짓)을 나타낸다. C에서는 0을 FALSE로 나머지 숫자는 TRUE로 인식한다. 그러나 이러한 방식은 Boolean 자료형을 직관적으로 나타내기 어렵다. C89에서는 Boolean 자료형을 지원하지 않고 C99부터 _Bool 형식을 지원한다. _Bool은 무부호 정수형 변수로 0 또는 1만 할당할 수 있고, 0이 아닌 값은 자동으로 1로 변환한다.
C언어가 오래 전 개발된 언어이다 보니 CPU 명령어가 만들어진 방식을 참고했다. 그렇기 때문에 python과 같이 TRUE, FALSE가 아닌 0은 FALSE 나머지는 TRUE로 인식한다.
숫자로 Boolean을 표현하면 가독성이 좋지 않다. define을 활용해 개선할 수 있고,
- C89
#include <stdio.h>
#define TRUE 1
#define FALSE 0
#define BOOL int
int main(void)
{
BOOL boolean;
printf("숫자를 입력하세요: ");
scanf("%d", &boolean);
if (boolean == FALSE){
printf("입력한 값은 FALSE를 나타냅니다.\n");
}
else{
printf("입력한 값은 TRUE를 나타냅니다.\n");
}
return 0;
}
- C99
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int main(void)
{
_Bool a;
a = 1;
if (a){
printf("TRUE\n");
}
else{
printf("FALSE\n");
}
return 0;
}
- <stdbool.h>
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
bool a = false;
if (a){
printf("a is TRUE\n");
}
else{
printf("a is FALSE\n");
}
return 0;
}
stdbool.h 헤더에서 bool 사이즈는 1byte이다. 참고로 char가 1byte, short가 2bytes, int가 4bytes이다.
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
printf("bool size is %lubyte\n", sizeof(bool));
return 0;
}
6. 자료형 변환(Type conversion)
Type casting이라고도 한다. 자료형의 표현 범위가 넓은 쪽으로 변환하는 것을 Type promotion(형 확장)이라고 하며, 표현 범위가 낮은 쪽으로 변환하는 것을 형 축소(Type demotion)라고 한다. 형 확장은 값의 손실이 없기 때문에 컴파일러가 알아서 처리할 수 있으나, 형 축소의 경우 값의 손실이 발생하기 때문에 컴파일러에서 경고를 발생시킽다.
6.1. 암시적 형 변환
Implicit type conversion, 자료형의 크기가 다른 값을 연산할 때 자동으로 자료형이 큰 값으로 변환(Type promotion)된다.
- e.g.
#include <stdio.h>
int main(void)
{
int a = 9;
float b = 1.1F;
printf("a * b = %.1f\n", a * b);
return 0;
}
a * b = 9.9
Program ended with exit code: 0
6.2. 명시적 형 변환
(<data type>) <variable> or <value>
Explicit type conversion, Type casting이라고도 한다. 자료형을 명시적으로 지정하여 변환하기 때문에 자료형 축소(Type demotion) 시 컴파일 경고가 나타나지 않는다.
- e.g.1
#include <stdio.h>
int main(void)
{
int a = 10;
float b = 9.99;
int c;
c = (int) a * b;
printf("c = %d\n", c);
printf("(int)a * b = %f\n", (int)a * b);
printf("a * (int)b = %d\n", a * (int)b);
printf("a * b = %f\n", a * b);
printf("a * b = %.4f\n", a * b);
return 0;
}
c = 99
(int)a * b = 99.899994
a * (int)b = 90
a * b = 99.899994
a * b = 99.9000
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
int a = 10, b = 9;
float res_1 = a / b;
float res_2 = (float) a / b;
printf("res_1 = %f\n", res_1);
printf("res_2 = %f\n", res_2);
return 0;
}
res_1 = 1.000000
res_2 = 1.111111
Program ended with exit code: 0
res_1은 int와 int가 연산되었기 때문에 소수점 이하가 잘린 값이 Register에 임시 저장된 후 float형 res_1 변수에 할당된다. 반면 res_2는 float과 int 연산이기 때문에 Implicit type conversion(암시적 형변환)이 발생해 float으로 계산된 값이 Register에 임시 저장된 후 float형 res_2 변수에 할당된다.
서로 다른 자료형을 계산할 때는 값의 잘림을 유의해야 한다.
7. 상수(Constant)
const <data type> <variable> = <literal>;
상수는 처음 선언할 때 값을 할당한 이후 값을 바꿀 수 없다. 반대로 변수는 언제든 값을 바꿀 수 있다. 주의할 점은 선언과 동시에 값을 할당해야 한다.
- e.g.
#include <stdio.h>
int main(void)
{
const int a = 1;
printf("a is %d\n", a);
a = 2; // Cannot assign to variable 'a' with const-qualified type 'const int'
printf("a is %d\n", a);
return 0;
}
ERROR
8. 입출력
8.1. 입력
8.1.1. sacnf()
scanf(<“data type”>, <&variable_1>, <&variable_2>…)
변수를 선언하고 입력 받을 변수의 서식지정자와 할당할 변수를 입력한다. 이 때 변수는 메모리 주소값으로 입력해야 한다. 따라서 일반적으로 할당할 변수 앞에는 &를 입력해야 한다. 반대로 배열이나, 포인터 변수의 경우 그대로 입력한다.
scanf에서 %i는 8, 10, 16진수 모두 입력할 수 있다. 반면 %d는 10진수 정수만 입력할 수 있다.
scanf는 일반적으로 처음 C를 접할 때 배우는 용도로 사용한다. 데이터를 문자 형식으로 받아 숫자로 변환하는 방식이 바람직하다. 나중에 알아보자.
공백까지 포함해서 입력을 받으려면 서식지정자를 %[^\n]s로 사용한다.
- e.g.1
#include <stdio.h>
int main(void)
{
int apple, num;
printf("사과의 가격과 구매 수량을 입력하십시오: ");
scanf("%d %d", &apple, &num);
printf("총 금액은 %d원 입니다.\n", apple * num);
return 0;
}
사과의 가격과 구매 수량을 입력하십시오: 1000 9
1000총 금액은 9000원 입니다.
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
double apple, num;
printf("사과의 가격과 구매 수량을 입력하십시오: ");
scanf("%lf, %lf", &apple, &num);
printf("총 금액은 %.0f원 입니다.\n", apple * num);
return 0;
}
사과의 가격과 구매 수량을 입력하십시오: 1000, 9
1000총 금액은 9000원 입니다.
Program ended with exit code: 0
double은 printf에서 서식지정자로 %f를 사용해도 되지만, scanf에서는 서식지정자로 %lf를 사용해야 한다.
여러개를 입력 받을 때는 설정한 형식 대로 입력해야 한다. 예컨대 “%d %d”이면 입력할 때 1000 9로 입력을 하고 “%d, %d”이면 1000, 9로 입력해야 한다.
8.1.2. getchar()
int 값을 반환하기 때문에 char가 아닌 int로 할당해도 된다. scanf()와 printf()를 사용하는 것보다 빠르다.
- e.g.
#include <stdio.h>
int main(void)
{
printf("입력하세요: ");
char c = getchar();
putchar(c);
printf("\n%c\n", c);
printf("%dbytes\n", sizeof(getchar()));
return 0;
}
입력하세요: abc
a
a
4bytes
Program ended with exit code: 0
char에는 문자 하나만 할당할 수 있기 때문에 나머지는 인식하지 않는다.
8.2. 출력
8.2.1. printf()
printf(<string>, <expr1>, <expr2>, …);
-
- expr
- expression, 임의의 표현식
- 원형
printf(/<const char *restrict format, …/>)
-
- format
- stdout을 위해 입력하는 문자열
- Format tags prototype is %[flags][width][.precision][length]specifier
8.2.2. putchar()
putchar(<variable>);
9. 연산자(Operator)
9.1. 산술 연산자
Arithmetic operator, 수의 계산을 위한 연산자
| Operator | Description |
|---|---|
| + | 더하기 |
| - | 빼기 |
| * | 곱하기 |
| / | 나누기 |
| % | 나머지 |
나머지 계산은 정수에서만 가능하다. 실수의 나머지는 math.h 헤더의 fmodf, fmod, fmodl 함수를 활용해 구할 수 있다. 그러나 실수의 나머지가 필요한가에 대해 생각해볼 필요가 있다. 정수를 나눌 때는 소수점을 표현할 수 없어 나머지를 활용하는 것이나, 실수는 나눈 값 전부를 표현할 수 있기 때문에 특별한 이유가 없는 이상 사용할 필요가 없다. 정수의 몫과 나누기는 초를 시간으로 반환할 때 사용할 수 있다. 예컨대 1100 / 60과 1100 % 60을 하게 되면 18분 20초를 계산할 수 있다.
5자리 정수를 입력 받아 1의 자리부터 10,000의 자리까지 숫자 출력하기.
- e.g.
#include <stdio.h>
int main(void)
{
int n0, n1, n2, n3, n4, n5;
scanf("%d", &n0);
n1 = n0 % 10;
n2 = n0 % 100 / 10 ;
n3 = n0 % 1000 / 100;
n4 = n0 % 10000 / 1000;
n5 = n0 / 10000;
printf("%d %d %d %d %d\n", n1, n2, n3, n4, n5);
return 0;
}
음수의 나머지 계산
- e.g.
#include <stdio.h>
int main(void)
{
printf("%.9f\n", -10.0 / 3.0);
printf("%d\n", -10 / 3);
printf("%d\n", 10 / 6);
return 0;
}
-3.333333333
-3
1
Program ended with exit code: 0
C99에서 나머지 연산은 a = (a / b) * b + a % b로 정의한다.
예컨대 10 % 3은 10 / 3 = 3 이므로 3 * 3 + 10 % 3으로 나머지는 1이다.
-10 % 3은 -10 = -3 * 3 + (-10 % 3)으로 나머지는 -1이다.
-10 % -3은 -10 = 3 * -3 + (-10 % -3)으로 나머지는 -1이다.
즉 a 값에 따라 부호가 결정됨을 알 수 있다.
정수끼리 나눈 값이 실수일 때는 소수값을 버린다. 즉 몫을 취하고 나머지를 버린다. 또한 당연히 0으로 나눌 수는 없다.
9.2. 대입 연산자
Assignment Operator, 변수에 값을 할당하는 연산자
| Operator | Description |
|---|---|
| = | 할당 |
9.3. 복합 대입 연산자
Augmented(Compound) assignment operator, 산술식을 간소화하는 대입 연산자
| Operator | Description |
|---|---|
| += | a = a + n |
| -= | a = a - n |
| *= | a = a * n |
| /= | a = a / n |
- e.g.
#include <stdio.h>
int main(void)
{
int a = 0, b = 0;
a = a + 9;
b += 9;
printf("a is %d\n", a);
printf("b is %d\n", b);
return 0;
}
a is 9
b is 9
Program ended with exit code: 0
9.4. 증감 연산자
Increment and Decrement Operator, 값을 1씩 증가시키거나 감소시키는 연산자
| Operator | Description |
|---|---|
| ++ | +1 |
| – | -1 |
- e.g.
#include <stdio.h>
int main(void)
{
int a = 10;
printf("a++ is %d\n", a++);
printf("a is %d\n", a);
printf("++a is %d\n", ++a);
return 0;
}
a++ is 10
a is 11
++a is 12
Program ended with exit code: 0
- Prefix(전위형)
- 증감 후 결괏값을 출력한다. 위의 예에서
printf("a++ is %d\n", a ++);는 10이지만 이후 a값을 확인하면 11인 것을 알 수 있다. 그리고 더해진 11에서 ++a를 했기 때문에 12가 출력된다. - Postfix(후위형)
- 결괏값을 출력한 후 더한다.
9.5. 관계 연산자
Relational operator, 결괏값이 1이면 TRUE, 0이면 FALSE를 의미한다.
| Operator | Description |
|---|---|
| < | 왼쪽이 작다 |
| > | 왼쪽이 크다 |
| <= | 왼쪽이 작거나 같다 |
| >= | 왼쪽이 크거나 같다 |
- e.g.
#include <stdio.h>
int main(void)
{
printf("9 > 1 is %d\n", 9 > 1); // TRUE
printf("9 < 1 is %d\n", 9 < 1); // FALSE
return 0;
}
9 > 1 is 1
9 < 1 is 0
Program ended with exit code: 0
9.6. 동등 연산자
Equality operator, 값을 비교하는 연산자
| Operator | Description |
|---|---|
| == | equal(같다) |
| != | not equal(같지 않다) |
== & !=와 =를 반드시 구분하자. ==와 !=는 비교를, =는 할당을 의미한다.
!= not equal을 의미한다. 같지 않다로 생각하면 =!로 반대로 표기할 수 있으니 not equal로 생각하자.
9.6.1. 실수값의 비교
앞서 서술했듯 2진법 체계 하에서 실수는 정확한 값으로 표현되지 않을 수 있다. 따라서 실수 연산 값을 단순히 ==으로 비교하면 원하지 않은 결과가 발생할 수 있다. 오차를 감안해서 실수를 피교하려면 float.h 헤더의 FLT_EPSILON, DBL_EPSILON, LDBL_EPSILON을 각각 실수자료형에 맞게 사용하면 된다.
실수 값 비교에서 ERROR 발생
- e.g.
#include <stdio.h>
int main(void)
{
float a = 0.1F;
a = a * 9;
printf("%.10f\n", a);
if (a == 0.9F)
printf("True\n");
else
printf("False\n");
return 0;
}
0.9000000358
False
Program ended with exit code: 0
FLT_EPSILON를 활용한 실수 값 비교
#include <stdio.h>
#include <float.h>
#include <math.h>
int main(void)
{
float a = 0.1F;
a = a * 9;
printf("a is %.10f\n", a);
printf("0.9F is %.10f\n", 0.9F);
printf("|a - 0.9| is %.10f\n", fabsf(a - 0.9F));
if (fabsf(a - 0.9F) <= FLT_EPSILON)
printf("True\n");
else
printf("False\n");
return 0;
}
a is 0.9000000358
0.9F is 0.8999999762
|a - 0.9| is 0.0000000596
True
Program ended with exit code: 0
FLT.EPSILON은 float.h 헤더에 정의된 Machine epsilon 값으로 어떤 실수의 상대 오차는 항상 Machine epsilon 이하다. 따라서 math.h 헤더의 절대값 함수인 fabsf를 활용해 절대값이 Machine epsilon 값보다 작은지 확인하여 같은 값임을 확인할 수 있다.
Machine epsilon 값
- e.g.
#include <stdio.h>
#include <float.h>
int main(void)
{
printf("FLT_EPSILON is %.40G\n", FLT_EPSILON);
printf("DBL_EPSILON is %.40G\n", DBL_EPSILON);
printf("LDBL_EPSILON is %.40LG\n", LDBL_EPSILON);
return 0;
}
FLT_EPSILON is 1.1920928955078125E-07
DBL_EPSILON is 2.220446049250313080847263336181640625E-16
LDBL_EPSILON is 1.084202172485504434007452800869941711426E-19
Program ended with exit code: 0
9.7. 논리 연산자
Logical operator, 값의 논리 구조를 나타내는 연산자
| Operator | Description |
|---|---|
| ! | NOT(부정) |
| && | AND(논리 곱) |
| || | OR(논리 합) |
-
- &&
- IF. TRUE && TRUE THEN TRUE
- IF. TRUE && FALSE THEN FALSE
- IF. FALSE && TRUE THEN FALSE
- IF. FLASE && FALSE THEN FALSE
-
- ||
- IF. TRUE || TRUE THEN TRUE
- IF. TRUE || FALSE THEN TRUE
- IF. FALSE || TRUE THEN TRUE
- IF. FALSE || FALSE THEN FALSE
- 단락 평가(Short-circuit evalution)
- 첫 번째 값만으로 결과를 알 수 있으면 두 번째 값은 확인하지 않는 평가 방법
- FALSE && ? 이면 FLASE에서 계산을 종료하고 FALSE를 반환한다.
- TRUE || ? 이면 TRUE에서 계산을 종료하고 TRUE를 반환한다.
- num1 != 0 && (num2 / num1) < 10 처럼 분모가 0일 때 발생하는 ERROR를 사전에 방지할 수 있다.
- e.g.
#include <stdio.h>
int main(void)
{
int a = 1, b = 10;
printf("%d\n", a < 11 && b < 11); // TRUE && TRUE
printf("%d\n", a < 11 && b < 1); // TRUE && FALSE
printf("%d\n", a < 1 && b < 1); // FALSE && FALSE
printf("%d\n", a < 11 || b < 11); // TRUE || TRUE
printf("%d\n", a < 11 || b < 1); // TRUE || FALSE
printf("%d\n", a < 1 || b < 1); // FALSE || FALSE
return 0;
}
1
0
0
1
1
0
Program ended with exit code: 0
9.8. 조건 연산자
Conditional expression, 피연산자가 세개 필요하기 때문에 삼중 연산자, 삼항 연산자, Ternary operator로도 불린다.
| Operator |
|---|
| ? |
| : |
9.8.1. 조건 표현식
expr1 ? expr2 : expr3;
Condition ? true_value : false_value;
expr1이 TRUE면 expr2이고, expr1이 FALSE면 expr3이다.
조건 표현식은 가독성을 해칠 수 있다. 따라서 조건 표현식을 사용하는 것이 코드의 가독성을 높일 수 있을 때만 사용하는 것이 바람직하다.
- e.g.1
#include <stdio.h>
int main(void)
{
int a;
char *b;
printf("숫자를 입력하세요: ");
scanf("%d", &a);
if (a == 0){
b = "0";
}
else{
b = (a < 0 ? "음수" : "양수");
}
printf("%s\n", b);
return 0;
}
- e.g.2
#include <stdio.h>
int main(void)
{
int a;
char b;
printf("숫자를 입력하세요: ");
scanf("%d", &a);
b = (a >= 0 ? (a == 0 ? '0' : '+') : '-');
printf("%c\n", b);
return 0;
}
9.9. 비트 연산자
Bitwise operator, 과거 컴퓨터 메모리를 최대한 활용하기 위해 비트 연산을 수행했다. 그러나 현대는 비트단위를 통제해 얻는 편익보다 코드의 효율성이 더 중요하기 때문에 거의 사용하지 않는다.
| Operator | Description |
|---|---|
| & | Bitwise AND |
| | | Bitwise OR |
| ^ | Bitwise XOR |
| ~ | Bitwise NOT |
| « | Bitwise LEFT SHIFT |
| » | Bitwise RIGHT SHIFT |
-
- a = 11001, b = 10001일 때 (a와 b는 5bit)
- a & b = 10001
- a | b = 11001
- a ^ b = 01000
- ~ a = 00110
- a « 2 = 00100
- a » 2 = 00110
- e.g.1
#include <stdio.h>
int main(void)
{
int a = 10; // 1010
printf("a >> 1 is %d\n", a >> 1); // 101
printf("a >> 2 is %d\n", a >> 2); // 10
printf("a << 1 is %d\n", a << 1); // 10100
return 0;
}
a » 1 is 5
a » 2 is 2
a « 1 is 20
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
char unsigned a = 10; // 0000 1010
char b = -10; // 1 111 0110
char c = 80; // 0 101 0000
char d = c << 3;
printf("10 >> 3 = %d\n", a >> 3); // 0000 0001
printf("10 << 3 = %d\n", a << 3); // 0101 0000
printf("-10 >> 3 = %d\n", b >> 3); // 1 111 1110
printf("-10 << 3 = %d\n", b << 3); // 1 011 0000
printf("80 >> 3 = %d\n", c >> 3); // 0 000 1010
printf("80 << 3 = %d\n", c << 3); // 0 000 0000 0000 0000 0000 0010 1000 0000
printf("80 << 3 = %d\n", (char){c << 3}); // 1 000 0000
printf("80 << 3 = %d\n", d); // 1 000 0000
printf("%dbyte\n", sizeof(a >> 3));
printf("%dbyte\n", sizeof(a << 3));
printf("%dbyte\n", sizeof(b >> 3));
printf("%dbyte\n", sizeof(b << 3));
printf("%dbyte\n", sizeof(c >> 3));
printf("%dbyte\n", sizeof(c << 3));
printf("%dbyte\n", sizeof(d));
return 0;
}
10 » 3 = 1
10 « 3 = 80
-10 » 3 = -2
-10 « 3 = -80
80 » 3 = 10
80 « 3 = 640
80 « 3 = -128
80 « 3 = -128
4byte
4byte
4byte
4byte
4byte
4byte
1byte
Program ended with exit code: 0
a에는 양의 정수 즉 자연수 값을 할당할 수 있다. 반면 b는 음수와 양수 값을 할당할 수 있다. a를 shift하는 것은 큰 어려움이 없을 것이다. 그런데 b는 오른쪽으로 shift할 때 빈 자리에 1이 채워진다. 반대로 왼쪽으로 shift를 하면 0이 채워진다. 음수를 shift할 때 이 점을 상기해야 한다. 특히 signed를 shift할 때 음수와 양수가 변할 수 있으므로 주의하자.
printf("80 << 3 = %d\n", c << 3);의 값은 640이다. 의도한 것은 printf("80 << 3 = %d\n", d);의 값 -128이다. 이유는 CPU가 정수형 연산을 하기에 적합한 크기가 int형이기 때문이다. 그리고 int형은 위에서 언급한 Data Model에 따라 달라진다. 즉 32bit Register면 int도 4bytes를, 64bit Register면 int도 8bytes를 기본 공간으로 한다.
다시 말해 연산을 하면서 char나 short형이라도 기본적으로 int로 자동 형 변환하여 계산하기 때문에 발생하는 이슈이다.
(char){c « 3}와 char d에서 의도한 결과가 나오는 것은 Type demotion이 발생했기 때문이다.
참고자료
참고자료
「정수의 연산은 기본적으로 32bit기준에서 4바이트로 계산을 진행하는데 그 이유를 “대략..설명하자면” 로더가 로딩을 하여 프로세스가 시작되고 메모리(RAM)에서부터 I/O Bus를 통해서 명령어를 이동시키는(Fetch), Bus Interface에서부터 CPU의 Control Unit까지의 명령어의 데이터의 적재(Decode), CPU의 ALU가 명령어를 처리하기 까지(Execution), 데이터를 처리하는 모든 프로토콜(약속)이 모두 32bit의 기준이기 때문이다.
인용 부분은 데이터 처리 과정에 관한 것이므로 이해하지 않아도 된다.
64bit라면 8바이트로 계산을 진행한다. 위의 사례에서 (char){c « 3}와 char d는 char -> int -> char 총 두번의 형 변환이 발생한다. 이러한 연유로 일반적으로 정수를 계산할 때는 int를 사용하는 것이 속도 측면에서 유리하다.」
- 도움. 42SEOUL에서 블랙홀을 헤매는 동시에 잠실에서 치킨집을 운영하시는 익명의 누군가
9.10. 연산자 우선순위
Operator precedence 참고자료
| Precedence | Operator | Associativity |
|---|---|---|
| 1 | ++ (postfix) -- (postfix) () [] . |
Left-to-right |
| 2 | ++ (prefix) -- (prefix) + (Unary) - (Unary) ! ~ * (Indirection[Dereference]) &(Address-of) |
Right-to-left |
| 3 | *(Multiplication) /(Division) %(Remainder) |
Left-to-right |
| 4 | + - |
Left-to-right |
| 5 | « (Bitwise) » (Bitwise) |
Left-to-right |
| 6 | < <= > >= |
Left-to-right |
| 7 | = != |
Left-to-right |
| 8 | & (Bitwise) | Left-to-right |
| 9 | ^ (Bitwise) | Left-to-right |
| 10 | | (Bitwise) | Left-to-right |
| 11 | && | Left-to-right |
| 12 | || | Left-to-right |
| 13 | ?: = (Direct assignment) += -= *= /= %= «= (Bitwise) »= (Bitwise) &= (Bitwise) ^= (Bitwise) |= (Bitwise) |
Right-to-left |
| 14 | , | Left-to-right |
9.11. 기타연산자
-
- sizeof
- sizeof가 함수라고 오해하기 쉬우나, sizeof는 compile time에 사용되는 연산자다.
10. 조건문(if)
if로 조건을 정하고 조건이 TRUE면 if에 서술한 것을 출력한다. else는 if 조건이 FALSE일 경우 출력할 결과를 의미한다. 따라서 else는 조건이 없음을 알 수 있다. 한편 else if와 else는 if가 TRUE이면 실행되지 않는다. 또한 else를 생략할 수 있으나, 생략하는 것은 좋은 코드가 아니다.
if 조건문 끝에 ;를 붙이면 에러가 발생한다.
if (<condition>) {
<statements>;
}
else if (<condition>){
<statements>;
}
else if (<condition>){
<statements>;
}
else {
<statements>;
}
- 계산 순서
1 2 3 4 5 if TRUE 종료 if FALSE else if TRUE 종료 else if FALSE else if TRUE 종료 else if FALSE else 종료
위와 아래는 어떤 차이가 존재할까? if_1, if_2, if_3은 각각 독립 시행되며, else는 if_3과 맞물린다. 따라서 else는 if_1과 if_2의 조건을 제외하지 않는다. 즉 오류 발생 확률이 존재한다. 그러므로 조건문을 작성할 때는 조건문의 프로세스와 종료 지점을 고려해야 한다.
if (<condition>) { // if_1
<statements>;
}
if (<condition>){ // if_2
<statements>;
}
if (<condition>){ // if_3
<statements>;
}
else {
<statements>;
}
- 계산 순서
1 2 3 if TRUE (if_1) 종료 if TRUE (if_2) 종료 if TRUE (if_3) 종료 if FALSE (if_3) else 종료
- e.g.
#include <stdio.h>
int main(void)
{
int a;
printf("정수를 입력하세요: ");
scanf("%d", &a);
if (0 < a){
printf("양수\n");
}
else if (a == 0){
printf("0\n");
}
else{
printf("음수\n");
}
return 0;
}
else if를 사용하지 않고 표현하면 아래와 같다.
- e.g.
#include <stdio.h>
int main(void)
{
int a;
printf("정수를 입력하세요: ");
scanf("%d", &a);
if (0 < a){
printf("양수\n");
}
else{
if (a == 0){
printf("0\n");
}
else{
printf("음수\n");
}
}
return 0;
}
실수를 방지하는 코드
- e.g.
int main(void)
{
int a = 1;
if (a = 0){
printf("%d\n", a);
}
else{
printf("FALSE\n");
}
return 0;
}
위의 코드를 살펴보자. a값의 할당을 if에서 다시 하게 된다. 의도는 비교연산자 ==였을 것이다. 컴파일러에 따라 경고를 주지만, ERROR가 발생하지는 않는다. 따라서 literal == variable 형식을 사용하면 literal = variable로 잘못 입력했을 때 literal에 변수를 할당할 수 없어 ERROR가 발생한다. 그러나 variable = variable일 때는 알 수 없다는 한계가 존재한다.
- e.g.
#include <stdio.h>
int main(void)
{
int a = 1;
if (0 = a){ // Expression is not assignable
printf("%d\n", a);
}
else{
printf("FALSE\n");
}
return 0;
}
11. 분기문(switch)
case에는 조건식이나 변수를 지정할 수 없다. 즉 상수(<constant-expression>)만 입력 가능하다. switch를 선언하게 되면 case의 개수에 따라 jump table을 생성한다. jump table은 0부터 할당되며 생성된 후 <expression>과 일치하는 case <constant-expression>로 Computed jump를 하고 그 이후의 <statements>를 출력한다. 따라서 default의 순서는 상관 없으나 나머지 case의 순서에 따라 결괏값이 달라질 수 있다.
if가 else if, else 순서로 확인하기 때문에 상대적으로 연산 횟수가 많다. 반면, switch는 바로 case로 jump하기 때문에 연산 횟수가 적다는 장점이 있다.
break가 없으면 일치하는 case를 찾은 뒤 그 이후의 statements를 모두 출력한다. 따라서 break를 통해 원하는 case를 출력한 뒤 swich를 빠져나갈 수 있도록 구성해야 한다.
<constant-expression>는 char를 포함한 정수 자료형만 사용 가능하다. 즉 실수 자료형은 사용할 수 없다.
switch ( <expression> ) {
case <constant-expression>:
<statements>;
break; // switch 종료
case <constant-expression>:
<statements>;
break; // switch 종료
default:
<statements>; // case에 해당하지 않을 때 기본값
break; //switch 종료
}
- e.g.
#include <stdio.h>
int main(void)
{
int a;
printf("5점 만점으로 별점을 부여하십시오: ");
scanf("%d", &a);
switch (a){
case 0:
printf("☆☆☆☆☆\n");
break;
case 1:
printf("★☆☆☆☆\n");
break;
case 2:
printf("★★☆☆☆\n");
// break;
case 3:
printf("★★★☆☆\n");
// break;
case 4:
printf("★★★★☆\n");
break;
case 5:
printf("★★★★★\n");
break;
default:
printf("잘못된 점수입니다.\n");
break;
}
return 0;
}
5점 만점으로 별점을 부여하십시오: 2
★★☆☆☆
★★★☆☆
★★★★☆
Program ended with exit code: 0
break를 생략해 or 표현하기
- e.g.
#include <stdio.h>
int main(void)
{
int a;
printf("5점 만점으로 별점을 부여하십시오: ");
scanf("%d", &a);
switch (a){
case 0:
case 1:
case 2:
printf("☆☆☆☆☆~★★☆☆☆\n");
break;
case 3:
case 4:
case 5:
printf("★★★☆☆~★★★★★\n");
break;
default:
printf("잘못된 점수입니다.\n");
break;
}
return 0;
}
{}를 활용해 case 안에서 변수 선언하기
- e.g.
#include <stdio.h>
int main(void)
{
int a;
switch (a){
case :
{
int b = a;
printf("");
break;
}
default:
break;
}
}
12. 반복문(Iteration statements)
12.1. for
반복 횟수가 정해져 있을 때 사용한다. C99부터 초기식에서 변수를 선언할 수 있고 선언한 변수는 Loop body에서만 사용할 수 있다. 이전 버전에서는은 for loop 외부에서 변수를 선언해야 한다.
for (<initialization>; <condition>; <increment/decrement>){ // Loop statement
<statements>
}
-
- initialization
- Loop index, 초기식
-
- condition
- 조건식, 조건이 TRUE면 for 루프 반복, 조건이 FALSE면 루프 종료
-
- increment/decrement
- 변화식
- e.g.
int main(void)
{
int sum = 0;
int i = 0;
for (i; i < 10; i++){
printf("i = %d\n", i);
sum = sum + i;
}
printf("sum = %d\n", sum);
printf("i = %d\n", i);
return 0;
}
i = 0
i = 1
i = 2
i = 3
i = 4
i = 5
i = 6
i = 7
i = 8
i = 9
sum = 45
i = 10
Program ended with exit code: 0
i++와 ++i는 모두 같은 결과를 출력한다. 왜냐하면 초기값과 조건을 비교한 뒤 loop body를 수행 한 후 변화값이 계산되기 때문이다. 즉 변화된 i는 다음 loop body에 적용되기 때문에 prefix와 postfix의 차이가 없는 것이다.
초기값으로 사용할 변수가 for loop 외부에서 선언되어 있다면 <initialization>를 생략할 수 있다.
- e.g.
#include <stdio.h>
int main(void)
{
int sum = 0;
int i = 0;
for (; i < 10; ++i){
printf("i = %d\n", i);
sum = sum + i;
}
printf("sum = %d\n", sum);
printf("i = %d\n", i);
return 0;
}
10번 째 loop를 보면 초기값이 9로 10미만으로 조건을 충족시키고, sum은 45가 되었으며, i는 10으로 증가했다. 11번 째에서는 초기값이 10으로 조건을 충족시키지 못했고 반복이 종료된다.
| 반복 횟수 | 초기값 | 조건 | sum | 변화값 |
|---|---|---|---|---|
| 1 | 0 | TRUE | 0 | 1 |
| 2 | 1 | TRUE | 1 | 2 |
| 3 | 2 | TRUE | 3 | 3 |
| 4 | 3 | TRUE | 6 | 4 |
| 5 | 4 | TRUE | 10 | 5 |
| 6 | 5 | TRUE | 15 | 6 |
| 7 | 6 | TRUE | 21 | 7 |
| 8 | 7 | TRUE | 28 | 8 |
| 9 | 8 | TRUE | 36 | 9 |
| 10 | 9 | TRUE | 45 | 10 |
| 11 | 10 | FALSE |
변수가 for loop에서 선언된 것인지, 외부에서 선언된 것인지 주의하자.
- e.g.
#include <stdio.h>
int main(void)
{
int sum = 0;
for (int i; i < 10; i++){
printf("i = %d\n", i);
sum = sum + i;
}
printf("sum = %d\n", sum);
printf("i = %d\n", i); // Use of undeclared identifier 'i'
return 0;
}
12.1.1. 2개 이상의 변수 사용
각 expression에 ,(Comma)를 통해 변수를 2개 이상 사용할 수 있다.
#include <stdio.h>
int main(void)
{
int i = 0;
for (int j = 0; i < 5 || j < 20; ++i, j = j+3){
printf("i = %d\n", i);
printf("j = %d\n", j);
}
printf("i = %d\n", i);
return 0;
}
i = 0
j = 0
i = 1
j = 3
i = 2
j = 6
i = 3
j = 9
i = 4
j = 12
i = 5
j = 15
i = 6
j = 18
i = 7
Program ended with exit code: 0
12.1.2. for Infinite loop
제어식(Controlling expression)을 모두 생략하면 무한루프가 된다.
무한루프는 반드시 탈출 조건을 설정해야 한다. 그렇지 않으면 무한히 반복한다.
- e.g.
#include <stdio.h>
int main(void)
{
int i = 0;
for (;;){
i = i + 1;
printf("%d\n", i);
if (i > 5){
break;
}
}
return 0;
}
1
2
3
4
5
6
Program ended with exit code: 0
12.2. while
조건이 TRUE일 때까지 반복한다. 즉 조건이 FALSE일 때 반복을 종료한다. 조건에 따라 1번도 loop를 실행하지 않을 수도 있다.
while (<condition>){ // Loop statement
<statements> // Loop body
}
12.2.1 while Infinite loop
조건을 1, 즉 TRUE로 만든다.
while (1){
<statements>
}
12.3. do while
while과 유사하지만 while이 조건을 먼저 검토하는 반면, do while은 조건을 loop body를 수행한 뒤 검토한다. 따라서 do while은 조건을 만족하는지에 상관 없이 적어도 1번은 loop를 실행한다.
다른 반복문과 다르게 while 뒤에 ;(semicolon)을 붙이는 것에 주의하자.
do{
<statements> // Loop body
} while (<condition>); // Loop statement
- e.g.1
#include <stdio.h>
int main(void)
{
int x = 0;
do {
printf("%d\n", x);
x = x - 1;
} while(0 < x);
return 0;
}
0
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
int x = 0;
while(0 < x){
printf("%d\n", x);
x = x - 1;
}
return 0;
}
e.g.1은 반복문이 1회 실행되어 0을 출력하는 반면, e.g.2는 반복문이 실행되지 않아 출력값이 존재하지 않는다.
12.3.1. do while Infinite loop
do{
<statements> // Loop body
} while (1); // Loop statement
반대로 한 번만 실행하는 루프를 구성할 수도 있다.
do{
<statements> // Loop body
} while (0); // Loop statement
12.4. 반복문을 활용한 구구단
- for
#include <stdio.h>
int main(void)
{
for (int x = 1; x < 10; ++x){
for (int y = 1; y < 10; ++y){
printf("%d * %d = %d\n", x, y, x * y);
}
}
return 0;
}
- for & while
#include <stdio.h>
int main(void)
{
int x = 1;
while (x < 10){
for (int y = 1; y < 10; ++y){
printf("%d * %d = %d\n", x, y, x * y);
}
x = x + 1;
}
return 0;
}
- while
#include <stdio.h>
int main(void)
{
int x = 1;
while (x < 10){
int y = 1;
while (y < 10){
printf("%d * %d = %d\n", x, y, x * y);
y = y + 1;
}
x = x + 1;
}
return 0;
}
12.5. 반복문 제어
일반적으로 반복문에서 break, continue, goto를 활용하는 것은 자제하는 것이 좋다. 코드의 가독성 측면에서 유리할 때만 제한적으로 사용해야 한다.
12.5.1. break
break가 포함된 구문의 반복을 강제로 종료한다.
break에는 ;(semicolon)이 필요하다.
while(){
for(){
break;
}
}
12.5.2. continue
loop body를 건너 뛰고 다음 반복을 실행한다.
continue에는 ;(semicolon)이 필요하다.
짝수만 더하기
- e.g.
#include <stdio.h>
int main()
{
int user_num;
int sum = 0;
int num = 1;
printf("숫자를 입력하세요: ");
scanf("%d", &user_num);
while (num <= user_num){
if (num % 2 == 0){
printf("num = %d\n", num);
sum = sum + num;
num = num + 1;
}
else{
num = num + 1;
continue;
}
}
printf("sum = %d\n", sum);
}
#include <stdio.h>
int main()
{
int user_num;
int sum = 0;
printf("숫자를 입력하세요: ");
scanf("%d", &user_num);
for (int num = 1; num <= user_num; ++num){
if (num % 2 == 0){
printf("num = %d\n", num);
sum = sum + num;
}
else{
continue;
}
}
printf("sum = %d\n", sum);
}
숫자를 입력하세요: 10
num = 2
num = 4
num = 6
num = 8
num = 10
sum = 30
Program ended with exit code: 0
12.5.3. goto
goto문이 있는 함수 내 label(표식)으로 이동한다. 따라서 이미 시행한 코드로 돌아갈 수도 있다. 그러나 goto는 코드의 가독성을 헤치므로 사용을 자제하는 것이 좋다.
label로 이동한 후 아래에 있는 모든 코드를 실행한다.
label도 변수명 규칙을 따른다. 변수명 규칙
goto <label>;
...
<label>:
<statements>
- e.g.
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
int a = 0;
while(true){
if ( a == 10){
goto EXIT;
}
printf("%d\n", a);
a = a + 1;
}
EXIT:
printf("종료\n");
return 0;
}
0
1
2
3
4
5
6
7
8
9
종료
Program ended with exit code: 0
13. 배열(Array)
<data type> <arrayName>[arraySize] = {<element0>, <element1> … };
| First Element | … | Last Element | ||
|---|---|---|---|---|
| Array[0] | Array[1] | … | Array[n-2] | Array[n-1] |
Index와 Index에 해당하는 data로 이루어진 자료 구조이다. 즉 Aggregate(집합) 변수로 여러 값을 저장할 수 있다. 또한, 각각의 element는 변수로 취급한다.
element가 size보다 작으면 나머지 element는 0이 할당된다.
Array의 데이터 공간은 data type의 byte * element 개수 만큼을 차지한다. 예를들어 int는 4bytes고 10개의 element를 초기화 했다면 그 배열이 차지하는 저장공간은 40bytes이다. 아래 예시를 살펴보면 4bit씩 공간이 증가하고 있음을 알 수 있다.
Array를 선언할 때 [arraySize]는 반드시 상수 또는 상수로 구성된 식이여야 한다. 따라서 변수는 사용할 수 없다. 단, 동적 메모리 할당Dynamic memory allocation을 사용하면 변수로 선언할 수 있다. 아래 예시는 변수를 const로 만들어 선언하는 예이다.
- e.g.1
#include <stdio.h>
int main(void)
{
int c;
printf("배열의 size를 입력하세요: ");
scanf("%d", &c);
const int b = c;
int a[b];
for (int i = 0; i < b; ++i){
a[i] = i;
printf("a[%d] = %d\n", i, a[i]);
}
return 0;
}
배열의 size를 입력하세요: 3
a[0] = 0
a[1] = 1
a[2] = 2
Program ended with exit code: 0
대다수의 프로그래밍 언어에서 index의 첫번째 항목을 0으로 시작한다. 그 이유는 메모리 주소가 0부터 시작하기 때문에 컴퓨터 입장에서 계산이 간편하기 때문이다. 따라서 Array[n-1]이 마지막 element인 것을 상기하자. 정의하지 않은 element(즉 Array[n]이상)을 출력하면 unexpected output(의도하지 않은 결괏값)이 출력된다.
- e.g.2
#include <stdio.h>
#define N 10
int main(void)
{
int arr[N] = {0, 1, 2, 3, 4, 5, 6, 7, 8};
for (int i = 0; i < N; ++i){
printf("arr[%d] = %d \n", i, arr[i]);
printf("&arr[%d] = %p \n", i, &arr[i]);
}
return 0;
}
arr[0] = 0
&arr[0] = 0x7ffeefbff4e0
arr[1] = 1
&arr[1] = 0x7ffeefbff4e4
arr[2] = 2
&arr[2] = 0x7ffeefbff4e8
arr[3] = 3
&arr[3] = 0x7ffeefbff4ec
arr[4] = 4
&arr[4] = 0x7ffeefbff4f0
arr[5] = 5
&arr[5] = 0x7ffeefbff4f4
arr[6] = 6
&arr[6] = 0x7ffeefbff4f8
arr[7] = 7
&arr[7] = 0x7ffeefbff4fc
arr[8] = 8
&arr[8] = 0x7ffeefbff500
arr[9] = 0
&arr[9] = 0x7ffeefbff504
Program ended with exit code: 0
- e.g.3
배열을 선언과 동시에 초기화할 때는 size를 지정하지 않아도 자동으로 element의 개수를 계산해 size를 지정한다.
#include <stdio.h>
int main(void)
{
int arr[] = {0, 1, 2};
printf("%d\n", arr[1]);
return 0;
}
- e.g.4 역배열 만들기
#include <stdio.h>
#define N 10
int main(void)
{
int arr[N] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int Inv[10]; // Inverse Array 선언
int i = 0, j = N -1;
for (; i < 10; ++i, --j){
Inv[i] = arr[j];
printf("Inv[%d] = %d\n", i, Inv[i]);
}
return 0;
}
Inv[0] = 9
Inv[1] = 8
Inv[2] = 7
Inv[3] = 6
Inv[4] = 5
Inv[5] = 4
Inv[6] = 3
Inv[7] = 2
Inv[8] = 1
Inv[9] = 0
Program ended with exit code: 0
- e.g.5 숫자 3개 입력 받아 평균 출력하기
#include <stdio.h>
#define N 3
int main(void)
{
int arr[N], sum = 0;
double aver = 0;
for (int i = 0; i < N; ++i){
printf("%d번째 숫자를 입력하세요: ", i + 1);
scanf("%d", &arr[i]);
sum = sum + arr[i];
}
aver = (double) sum / N;
printf("(%d + %d + %d) / %d = %.2f\n", arr[0], arr[1], arr[2], N, aver);
return 0;
}
1번째 숫자를 입력하세요: 1
2번째 숫자를 입력하세요: 1
3번째 숫자를 입력하세요: 2
(1 + 1 + 2) / 3 = 1.33
Program ended with exit code: 0
13.1. Designated initializer
<data type> <arrayName>[<arraySize>] = {[<i>] = <\(Arr_{i}\)>, [<j>] = <\(Arr_{j}\)> … }
지정 초기자, 특정 elements만 값을 지정하고 나머지는 0으로 배열을 지정하고 싶을 때 사용한다. 순서대로 입력할 필요는 없다.
C99부터 적용된다.
- e.g.1
#include <stdio.h>
int main(void)
{
const int x = 10;
int arr[x] = {[1] = 2, [5] = 6, [9] = 10};
// 동일함
// int arr[x] = {0, }; // 모든 elements를 0으로 초기화
// arr[1] = 2;
// arr[5] = 6;
// arr[9] = 10;
for (int i = 0; i < x; ++i){
printf("arr[%d] = [%d]\n", i, arr[i]);
}
return 0;
}
arr[0] = [0]
arr[1] = [2]
arr[2] = [0]
arr[3] = [0]
arr[4] = [0]
arr[5] = [6]
arr[6] = [0]
arr[7] = [0]
arr[8] = [0]
arr[9] = [10]
Program ended with exit code: 0
- e.g.2
#include <stdio.h>
int main(void)
{
const int x = 10;
int arr[x] = {0, };
arr[1] = 2;
arr[5] = 6;
arr[9] = 10;
for (int i = 0; i < x; ++i){
printf("arr[%d] = [%d]\n", i, arr[i]);
}
return 0;
}
arr[0] = [0]
arr[1] = [2]
arr[2] = [0]
arr[3] = [0]
arr[4] = [0]
arr[5] = [6]
arr[6] = [0]
arr[7] = [0]
arr[8] = [0]
arr[9] = [10]
Program ended with exit code: 0
왜 arr[x]를 0으로 초기화하지 않으면 배열의 값을 출력할 때 쓰레기 값(unexpected output)이 나올 수 있다.
13.2. Multi-dimensional Arrays
- 2D
- <data type> <arrayName>[arraySize_x][arraySize_y];
- 3D
- <data type> <arrayName>[arraySize_x][arraySize_y][arraySize_z];
다차원 배열, 2차원(Two-dimensional space) 행열과 3차원 등 n차원의 배열을 만들 수 있다. 하지만 데이터는 선형으로 저장되어 있다. 단지 인간의 이해를 돕기 위해 Table 또는 3D Cube로 상상하는 것이다. 따라서 인간이 상상하기 어려운 4차원 이상은 사용하지 않는 것이 좋다.
| [0, 0] | [0, 1] | [0, 2] | [0, 3] | … | [0, n] |
| [1, 0] | [1, 1] | [1, 2] | [1, 3] | … | [1, n] |
| [2, 0] | [2, 1] | [2, 2] | [2, 3] | … | [2, n] |
| [3, 0] | [3, 1] | [3, 2] | [3, 3] | … | [3, n] |
| … | … | … | … | … | … |
| [n, 0] | [n, 1] | [n, 2] | [n, 3] | … | [n, n] |
일반적으로 2 X 3 Matrix(행렬)은 가로가 2줄 세로가 3줄을 의미한다. 그리고 Array에서 2 X 3 행렬 또한 arr[2][3]이다. 아래 e.g.1이 2 X 3 Matrix이다. 그리고 e.g.2가 int형 2 X 3 Matrix가 저장된 데이터 형태를 의미한다. 그렇다면 1행에 할당된 메모리는 몇 byte일까? 정답은 12bytes다. e.g.1을 보자, 1행에는 3개의 데이터가 저장되어 있다. 그리고 e.g.2에서 arr[0] 즉 1행은 총 12bytes임을 알 수 있다.
그런데 다수의 책에서 Array에서 2차원 행렬을 arr[세로][가로]로 표현한다. 이는 아마 한 행(가로)에 3개의 공간이 할당되어 있음을 표현하기 위한 설명이라고 판단된다. 그러나 Matrix를 생각해보면 Row(행) X Column(열)이 정확한 표현이다. 단, sizeof(arr[0])는 한 행을 의미하고 한 행에는 Column수 만큼의 공간이 존재함을 주의하자.
또는 arr[y][x]로 표현할 수 있다. 아래와 같은 그래프를 상상해보자. y = -3, x = 2이다. 이때 y를 음수로 표기하는 이유는 배열이 위에서 아래 순서로 pointer가 할당되므로 이해하기 쉽도록 만든 것이다. x = 0, y = 0에서 (2, -3) 좌표를 기준으로 1을 한 칸으로 하는 그래프에 값을 할당한다고 생각해도 무방하다.
- e.g.1
| [0, 0] = 0 | [0, 1] = 1 | [0, 2] = 2 |
| [1, 0] = 3 | [1, 1] = 4 | [1, 2] = 5 |
- e.g.2
| 4bytes | 4bytes | 4bytes | 4bytes | 4bytes | 4bytes |
|---|---|---|---|---|---|
| [0, 0] = 0 | [0, 1] = 1 | [0, 2] = 2 | [1, 0] = 3 | [1, 1] = 4 | [1, 2] = 5 |
2 X 3 Matrix Array
- e.g.
#include <stdio.h>
int main(void)
{
const int x = 2;
const int y = 3;
int arr[x][y] = { {0, 1, 2},
{3, 4, 5} };
for (int i = 0; i < x; ++i){
printf("|");
for (int j = 0; j < y; ++j){
printf(" arr[%d][%d] = [%d] |", i ,j, arr[i][j]);
}
printf("\n");
}
return 0;
}
| arr[0][0] = [0] | arr[0][1] = [1] | arr[0][2] = [3] |
| arr[1][0] = [3] | arr[1][1] = [4] | arr[1][2] = [0] |
Program ended with exit code: 0
2 X 2 X 2 X 2 Array
- e.g.
#include <stdio.h>
int main(void)
{
int arr[2][2][2][2] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
for (int i = 0; i < 2; ++i){
for (int j = 0; j < 2; ++j){
for (int x = 0; x < 2; ++x){
for (int y = 0; y < 2; ++y){
printf("arr[%d][%d][%d][%d] = [%d]\n", i ,j, x, y, arr[i][j][x][y]);
}
}
}
}
return 0;
}
arr[0][0][0][0] = [0]
arr[0][0][0][1] = [1]
arr[0][0][1][0] = [2]
arr[0][0][1][1] = [3]
arr[0][1][0][0] = [4]
arr[0][1][0][1] = [5]
arr[0][1][1][0] = [6]
arr[0][1][1][1] = [7]
arr[1][0][0][0] = [8]
arr[1][0][0][1] = [9]
arr[1][0][1][0] = [10]
arr[1][0][1][1] = [11]
arr[1][1][0][0] = [12]
arr[1][1][0][1] = [13]
arr[1][1][1][0] = [14]
arr[1][1][1][1] = [15]
Program ended with exit code: 0
다차원 배열에서는 첫 번째 arraySize만 생략한 상태로 초기화할 수 있다. 즉 두 번째 arraySize부터는 생략하면 ERROR가 발생한다.
- e.f.
#include <stdio.h>
int main(void)
{
const int x = 4;
const int y = 2;
int arr[][y] = { {1, 2}, {3, 4}, {5, 6}, {7} };
// int arr[x][] = { {1, 2}, {3, 4}, {5, 6}, {7} };
// ERROR: Array has incomplete element type 'int []'
for (int i = 0; i < x; ++i){
for (int j = 0; j < y; ++j){
printf("arr[%d][%d] = [%d]\n", i ,j, arr[i][j]);
}
}
return 0;
}
arr[0][0] = [1]
arr[0][1] = [2]
arr[1][0] = [3]
arr[1][1] = [4]
arr[2][0] = [5]
arr[2][1] = [6]
arr[3][0] = [7]
arr[3][1] = [0]
Program ended with exit code: 0
13.3. sizeof를 활용한 배열 크기 도출
sizeof(<arrayName>) / sizeof(<data type>)
- Array가 사용하는 저장공간을 자료형으로 나누면 사용하고 있는 elements, 즉 arraySize를 알 수 있다. 이러한 방식을 사용하는 이유는 배열의 크기를 수정할 때 도움이 되기 때문이다. 만약 배열을 10 by 2로 수정하면 조건식과 배열 두 가지를 수정해야 하지만, sizeof 방식을 활용하면 조건식은 수정할 필요가 없다.
- sizeof(<arrayName>)
- Array가 사용하고 있는 저장공간
sizeof(<data type> - Array의 data type
- e.g.
#include <stdio.h>
int main(void)
{
const int y = 2;
int arr[][y] = {
{1, 2},
{3, 4},
{5, 6},
{7, }
};
// x와 y의 크기 도출 방법
printf("x = %d\n", sizeof(arr) / sizeof(arr[0]));
printf("x = %d\n", sizeof(arr) / sizeof(arr[0][0]) / y);
printf("y = %d\n", sizeof(arr[0]) / sizeof(arr[0][0]));
// arr[0][0]은 이차원 배열의 자료형 값을 의미한다.
int array_Size_x = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < array_Size_x; ++i){
for (int j = 0; j < y; ++j){
printf("arr[%d][%d] = [%d]\n", i ,j, arr[i][j]);
}
}
return 0;
}
x = 4
x = 4
y = 2
arr[0][0] = [1]
arr[0][1] = [2]
arr[1][0] = [3]
arr[1][1] = [4]
arr[2][0] = [5]
arr[2][1] = [6]
arr[3][0] = [7]
arr[3][1] = [0]
Program ended with exit code: 0
13.4. Decimal to Binary
// 10진수를 2진수로 바꾸기
#include <stdio.h>
int main(void)
{
int user_dec;
int arr[32] = {0, }; // 32bit size로 초기화
int i;
printf("숫자를 입력하세요: ");
scanf("%d", &user_dec);
printf("decimal %d to binary is ", user_dec);
for (i = 0; user_dec != 0; ++i){
arr[i] = user_dec % 2;
user_dec = user_dec / 2;
}
for (int j = i - 1; 0 <= j; --j){
printf("%d", arr[j]);
}
printf("\n");
}
숫자를 입력하세요: 100
100 binary = 1100100
Program ended with exit code: 0
13.5. 동적 할당을 활용한 배열
14. Pointer
<data type>* <pointerName>; <!– Pointer Declare –>
…
<pointerName> = &<variable>; <!– Pointer Assignment –>
…
*<pointerName> = <literal>; <!– Dereference –>
Pointer는 특정 데이터(변수)가 저장되어 있는 메모리 주소의 시작값을 보관하는 변수이다. Pointer도 변수이기 때문에 주소값 영역에 할당된 데이터는 언제든지 변경할 수 있다.
자료형을 선언하는 이유는 무엇일까? 만약 메모리 주소값만 알고 있다면 포인터를 역참조할 때 얼마나 읽어와야 할지 알 수 없다. 즉 자료형을 선언해야만 역참조 시 얼마큼 읽어오고 포인터와 정수의 연산에서 얼만큼 이동할 지 알 수 있다.
포인터는 뒤에서 부터 읽는 것이 해석하는데 수월하다. 예컨대 const int* p;는 변수, 포인터, 정수, 상수 순으로 읽은 뒤 변하지 않는(상수) 정수를 가리키는 포인터 변수로 해석한다.
-.e.g.1
#include <stdio.h>
int main(void)
{
char* cp = (char*)0x7ffc4cf2400;
int* ip = (int*)0x7ffc4cf2500;
printf("cp = %p\n", cp);
printf("cp = %p\n", cp + 1);
printf("\n");
printf("ip = %p\n", ip);
printf("ip = %p\n", ip + 1);
}
cp = 0x7ffc4cf2400
cp = 0x7ffc4cf2401
ip = 0x7ffc4cf2500
ip = 0x7ffc4cf2504
Program ended with exit code: 0
일반적으로 *(Asterisk)는 data type 뒤에 붙이지만, int * Ptr, int *Ptr도 허용된다. 예를들어 int* ptr;은 int 자료형의 포인터 변수 ptr을 선언한 것이다. int*로 사용하는 것이 역참조 연산자와도 헷갈리지 않고 조금 더 가독성이 높다. 32bit CPU에서는 16진수 8자리(4bytes, 0x00000000 ~ 0xFFFFFFFF)에 저장되며, 64bit CPU는 16진수 16자리(8bytes, 0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF)에 저장된다.
초기화 하지 않은 포인터 변수에 값을 할당하거나, 역참조 연산자를 사용하는 것은 의도하지 않은 결과를 야기한다. 따라서 포인터를 NULL로 초기화하는 것이 좋다. 또는 assert 함수를 사용해 포인터가 NULL이면 프로그램을 종료시킬 수 있다.
- e.g.
#include <stdio.h>
int main(void){
int *pi = NULL;
if (pi == NULL){
printf("Error\n");
}
else{
// 할당, 역참조 등 pi 사용 가능
}
}
- e.g.
#include <stdio.h>
#include <assrt.h>
int main(void){
int *pi = NULL;
assrt(pi != NULL);
}
Pointer에 data type을 필요한 이유는 data type을 선언하지 않을 경우 Pointer는 주소의 시작값이기 때문에 시작값에서 얼마만큼의 주소값을 읽어와야 할지 알 수 없다. 즉 아래 예에서 Pointer의 data type을 선언하지 않으면, 변수 a는 0x7ffeefbff4fc에서 시작하지만 어디까지 a인지 알 수 없다. 예제에서는 int로 선언했기 때문에 0x7ffeefbff4fc부터 4bytes에 해당하는 공간이 a의 주소값 영역이 되는 것이다.
포인터 값은 실행 때마다 달라질 수 있다. 왜냐하면 코드가 동작하는 컴퓨터의 메모리 공간의 주소이기 때문에 휘발성 메모리인 RAM에서 삭제될 수 있기 때문이다. 이를 이해하면 당연히 컴퓨터마다 포인터 값은 다르단 것을 알 수 있다.
Linux와 OS X에서 서식지정자 %p를 활용하면 메모리 주소 앞에 0x가 붙고 높은 자리수의 0은 생략해서 출력한다.
int* p일 때 int*는 pointer to int라고 읽는다. 반대로 int a일 때 &a는 address of int라고 읽는다.
-
- &(Ampersand)
- Address operator, 피연산자의 주소값을 호출한다.
-
- %p
- 서식지정자로 16진수의 주소값을 출력한다.
- OS X에서는 서식지정자 %p로 출력하면 메모리 주소 앞에 0x가 붙어 16진수임을 표시하고, 앞의 0은 생략한다.
-
- *(Asterisk)
- <data type>* <pointerName>에서 *는 Pointer를 선언 한다.
- *<pointerName> = <literal>에서 *는 Dereference(= indirection) operator(역참조 연산자)로, 주소값에 대응되는 데이터를 호출한다.
- 즉 *는 data type과 함께 포인터를 선언할 때 사용하는 동시에, 포인터 변수에 사용하면 메모리 공간에 할당된 데이터를 호출한다. 한편 *는 피연산자 사이에 있을 때는 곱셈 연산자로 해석하며, *가 변수에 사용되면 Unary(단항 연산자)로 해석한다.
- e.g.2
#include <stdio.h>
int main(void)
{
int* Ptr; // Pointer Variable 선언
int a = 9;
Ptr = &a; // 변수 a의 메모리 주소값을 Pointer Variable에 할당
*Ptr = 4; // 변수 a의 메모리 주소값에 4를 할당
printf("&a is %p\n", &a);
printf("&Ptr is %p\n", Ptr);
printf("a is %d\n", a);
printf("*Ptr is %d\n", *Ptr);
return 0;
}
&a is 0x7ffeefbff4fc
&Ptr is 0x7ffeefbff4fc
a is 4
*Ptr is 4
Program ended with exit code: 0
- e.g.3
배열 이름은 배열의 포인터 값을 가진다. 따라서 배열에 정수를 더해 배열 값을 이동할 수 있다.
#include <stdio.h>
int main(void)
{
int arr[5] = {0, 1, 2, 3, 4};
for (int i = 0; i < 5; ++i){
printf("arr[%d] = %d\n", i, arr[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("arr[%d] = %d\n", i, *(arr + i));
}
return 0;
}
arr[0] = 0
arr[1] = 1
arr[2] = 2
arr[3] = 3
arr[4] = 4
arr[0] = 0
arr[1] = 1
arr[2] = 2
arr[3] = 3
arr[4] = 4
Program ended with exit code: 0
- e.g.4
#include <stdio.h>
int main(void)
{
int arr[5] = {0, 1, 2, 3, 4};
int* array[5] = {5, 6, 7, 8 ,9};
printf("arr = %p\n", arr);
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[1] = %p\n", &arr[1]);
printf("&arr[2] = %p\n", &arr[2]);
printf("&arr[3] = %p\n", &arr[3]);
printf("&arr[4] = %p\n", &arr[4]);
return 0;
}
arr = 0x7ffeefbff430
&arr[0] = 0x7ffeefbff430
&arr[1] = 0x7ffeefbff434
&arr[2] = 0x7ffeefbff438
&arr[3] = 0x7ffeefbff43c
&arr[4] = 0x7ffeefbff440
Program ended with exit code: 0
#include <stdio.h>
int main(void)
{
int arr[5] = {0, 1, 2, 3, 4};
int* array[5] = {5, 6, 7, 8 ,9};
printf("array = %p\n", array);
printf("&array[0] = %p\n", &array[0]);
printf("&array[1] = %p\n", &array[1]);
printf("&array[2] = %p\n", &array[2]);
printf("&array[3] = %p\n", &array[3]);
printf("&array[4] = %p\n", &array[4]);
return 0;
}
array = 0x7ffeefbff400
&array[0] = 0x7ffeefbff400
&array[1] = 0x7ffeefbff408
&array[2] = 0x7ffeefbff410
&array[3] = 0x7ffeefbff418
&array[4] = 0x7ffeefbff420
Program ended with exit code: 0
#include <stdio.h>
int main(void)
{
int arr[5] = {0, 1, 2, 3, 4};
int* array[5] = {5, 6, 7, 8 ,9};
printf("sizeof(arr) = %d\n", sizeof(arr)); // 4 * 5, int is 4bytes.
printf("sizeof(array) = %d\n", sizeof(array)); // 8 * 5, pointer is 8bytes.
printf("sizeof(*array) = %d\n", sizeof(*array)); // *array is array[0]
}
sizeof(arr) = 20
sizeof(array) = 40 LP64
sizeof(*array) = 8
Program ended with exit code: 0
#include <stdio.h>
iint main(void)
{
int arr[5] = {0, 1, 2, 3, 4};
int* array[5] = {0, };
array[1] = arr;
array[1][3] = 99;
// arr[3] = 99;
// *(array[1] + 3) = 99;
// *(*(array + 1) + 3) = 99;
for (int i = 0; i < 5; ++i){
printf("&array[%d] = %p\n", i, &array[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("&array[%d] = %p\n", i, array[i]);
}
printf("\n");
printf(" array[1] = %p\n", array[1]);
printf(" &arr[0] = %p\n", &arr[0]); // array[1] = arr[0] = arr
// array[1]에 arr[0]의 메모리 주소가 할당된 상태이다.
printf("\n");
printf("array[1][3] = %d\n", array[1][3]);
printf("arr[3] = %d\n", arr[3]);
printf("*(arr + 2) = %d\n", *(arr + 3));
printf("*(*(array + 1) + 3) = %d\n", *(*(array + 1) + 3));
printf("\n");
for (int i = 0; i < 5; ++i){
printf("arr[%d] = %d\n", i, arr[i]);
}
return 0;
}
&array[0] = 0x7ffeefbff3b0
&array[1] = 0x7ffeefbff3b8
&array[2] = 0x7ffeefbff3c0
&array[3] = 0x7ffeefbff3c8
&array[4] = 0x7ffeefbff3d0
&array[0] = 0x0
&array[1] = 0x7ffeefbff3e0
&array[2] = 0x0
&array[3] = 0x0
&array[4] = 0x0
array[1] = 0x7ffeefbff3e0
&arr[0] = 0x7ffeefbff3e0
array[1][3] = 99
arr[3] = 99
*(arr + 2) = 99
*(*(array + 1) + 3) = 99
arr[0] = 0
arr[1] = 1
arr[2] = 2
arr[3] = 99
arr[4] = 4
Program ended with exit code: 0
- array[1] = arr, visualization
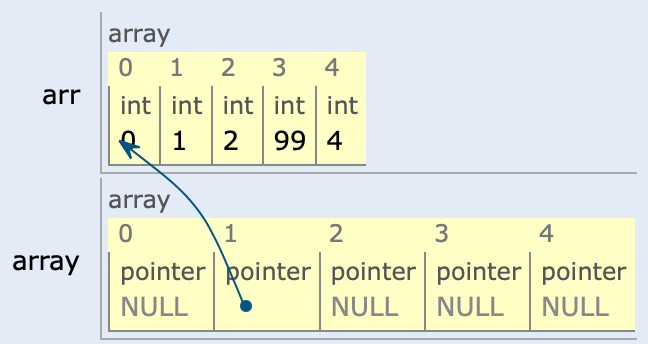
- e.g.5
포인터는 배열이 아니다.
#include <stdio.h>
int main(void)
{
char arr[] = "abcde";
char* str = "abcde";
// char* str = "abcde"와 같은 표현
// char* str;
// str = "abcde";
for (int i = 0; i < 5; ++i){
printf("arr[%d] = %c\n", i, arr[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("str[%d] = %c\n", i, str[i]);
}
// Error
// str[1] = 'z';
// str 포인터는 "abcde"의 주소를 담고 있기 때문에 각각의 값을 가진 것이 아니다.
// 따라서 값을 변경할 수 없는 상수처럼 취급한다.
printf("\n");
printf("str = %p\n", str);
printf("&\"abcde\" = %p\n", &"abcde");
printf(" \"abcde\" = %p\n", "abcde");
return 0;
}
arr[0] = a
arr[1] = b
arr[2] = c
arr[3] = d
arr[4] = e
str[0] = a
str[1] = b
str[2] = c
str[3] = d
str[4] = e
str = 0x100003f12
&”abcde” = 0x100003f12
“abcde” = 0x100003f12
Program ended with exit code: 0
#include <stdio.h>
int main(void)
{
char arr[] = "abcde";
char* str = "abcde";
for (int i = 0; i < 5; ++i){
printf("str[%d] = %p\n", i, &str[i]);
}
// str[5]는 '\0' 즉 null이다.
printf("\n");
for (int i = 0; i < 6; ++i){
printf("str[%d] = %c\n", i, str[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("arr[%d] %%p = %p\n", i, &arr[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
arr[i] = arr[i] + 2;
printf("arr[%d] = %c\n", i, arr[i]);
}
return 0;
}
str[0] = 0x100003f12
str[1] = 0x100003f13
str[2] = 0x100003f14
str[3] = 0x100003f15
str[4] = 0x100003f16
str[0] = a
str[1] = b
str[2] = c
str[3] = d
str[4] = e
str[5] = �
arr[0] = 0x7ffeefbff446
arr[1] = 0x7ffeefbff447
arr[2] = 0x7ffeefbff448
arr[3] = 0x7ffeefbff449
arr[4] = 0x7ffeefbff44a
arr[0] = c
arr[1] = d
arr[2] = e
arr[3] = f
arr[4] = g
Program ended with exit code: 0
- e.g.6
포인터 문자열 배열에 할당하기
#include <stdio.h>
int main(void)
{
char* str = "abcde";
char temp[5] = {};
for (int i = 0; i < 5; ++i){
printf("str[%d] = %c\n", i, str[i]);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("str[%d] = %p \n", i, &str[i]);
}
printf("\n");
for (int i = 0; i < 5 ; ++i){
printf("&str[%d] = %p\n", i, &str[i]);
temp[i] = str[i];
printf("temp[%d] = %c\n", i, temp[i]);
}
return 0;
}
str[0] = a
str[1] = b
str[2] = c
str[3] = d
str[4] = e
str[0] = 0x100003f6a
str[1] = 0x100003f6b
str[2] = 0x100003f6c
str[3] = 0x100003f6d
str[4] = 0x100003f6e
&str[0] = 0x100003f6a
temp[0] = a
&str[1] = 0x100003f6b
temp[1] = b
&str[2] = 0x100003f6c
temp[2] = c
&str[3] = 0x100003f6d
temp[3] = d
&str[4] = 0x100003f6e
temp[4] = e
Program ended with exit code: 0
14.1. Constant & Pointer
14.1.1. pointer to constant
const <data type> *<pointerName> 또는 <data type> const *<pointerName>
상수를 가르키는 포인터, 포인터가 가르키는 것이 상수이지 포인터가 상수는 아니다. 따라서 포인터 변수에 다른 변수를 할당하는 것은 가능하지만 포인터를 역참조해 값을 할당하는 것은 불가하다.
#include <stdio.h>
int main(void)
{
int a = 10;
const int b = 100;
int* p;
const int* p_t_c;
p_t_c = &a;
printf("%d\n", *p_t_c);
p_t_c = &b;
printf("%d\n", *p_t_c);
// *p_t_c = 1000; // Read-only variable is not assignable
printf("\n");
p = &a;
printf("%d\n", *p);
p = &b;
printf("%d\n", *p);
*p = 1000;
printf("%d\n", *p);
}
10
100
10
100
1000
Program ended with exit code: 0
14.1.2. constant pointer
<data type>* const <pointerName>
상수 포인터, 포인터가 상수이기 때문에 포인터에 처음 할당된 값을 바꿀 수 없다. 그러나 포인터에 할당된 값은 역참조를 통해 바꿀 수 있다.
#include <stdio.h>
int main(void)
{
int a = 10;
const int b = 100;
int* const p_t_c = &a;
// p_t_c = &b; // Cannot assign to variable 'p_t_c' with const-qualified type 'int *const'
printf("%d\n", *p_t_c);
*p_t_c = 20;
printf("%d\n", *p_t_c);
printf("%d\n", a);
}
10
20
20
Program ended with exit code: 0
14.1.3 constant pointer to constant
const <data type>* const <pointerName>
포인터가 가르키는 것과 포인터 모두 상수이다. 따라서 포인터에 처음 할당 된 값을 바꿀 수 없고, 역참조 값도 할당할 수 없다. 즉 메모리 주소와 메모리 주소에 저장된 값 모두를 바꿀 수 없다.
14.2. void Pointer
void <pointerName>
자료형이 다른 포인터끼리는 메모리 주소를 할당할 수 없지만 void 포인터는 모든 자료형의 포인터를 할당할 수 있다. 또한 모든 자료형의 포인트에 void 포인터를 할당할 수도 있다. 단 void 포인터는 자료형이 정해지지 않았기 때문에 역참조가 불가하다. void 포인터를 사용하는 이유는 함수에서 다른 자료형을 받아들이거나, 함수의 반환 포인터를 다양한 자료형으로 된 포인터에 저장할 때, 자료형을 숨기고 싶을 때 사용한다.
void 포인터는 각각 서로 다른 메모리 주소값을 가지고 있기 때문에 같을 수 없다. 다만, NULL 포인터는 모두 동일하게 취급한다.
14.3. Double Pointer(이중 포인터)
<data type>** const <pointerName>
*를 두 번 사용한 포인터의 포인터를 의미한다. 삼중포인터는 *를 세 번 사용한다. 참고로 arr[3][4]은 *(*(arr + 3) + 4)으로 해석된다. int** p는 pointer to pointer to int로, 포인터를 카리키는 int 자료형의 포인터를 의미한다.
*p는 포인터 p에 할당한 값을 역참조한 값 a을 의미하고,
p는 포인터 p에 할당한 값 &a을 의미하며,
&p는 포인터 p의 값, 즉 p의 메모리 주소 값을 의미한다.
이를 다시 이중 포인터에 적용해보자. 우리는 아래서 pp에 &p를 할당한다.
*pp는 포인터 pp에 할당한 값을 역참조한 값이다. 따라서 &p를 역참조하면 p가 된다.
**pp를 분해하면 *(pp)로 쓸 수 있다. 즉 *(pp)는 *(p)를 의미하고 *p는 a를 의미한다.
pp는 &p를 의미하고,
&pp는 pp의 메모리 주소 값을 의미한다.
참고자료1
- e.g.
#include <stdio.h>
int main(void)
{
int a = 10;
int* p;
int** pp;
printf("&a = %p\n", &a);
printf("\n");
p = &a;
printf("*p = %d\n", *p); // *p = a
printf("p = %p\n", p); // p = &a
printf("&p = %p\n", &p);
printf("\n");
pp = &p;
// pp = p;
// Incompatible pointer types assigning to 'int **' from 'int *'; take the address with &
printf("**p = %d\n", **pp); // **pp = *(*pp) = *p = a
printf("pp = %p\n", pp); // pp = &p
printf("&pp = %p\n", &pp);
printf("*pp = %p\n", *pp); // *pp = p = &a
return 0;
}
&a = 0x7ffeefbff3f8
*p = 10
p = 0x7ffeefbff3f8
&p = 0x7ffeefbff3f0
**p = 10
pp = 0x7ffeefbff3f0
&pp = 0x7ffeefbff3e8
*pp = 0x7ffeefbff3f8
Program ended with exit code: 0
14.4. Pointer 연산
포인터 변수 간 덧셈, 나눗셈, 곱셈은 불가하다. 생각해보자, 포인터는 메모리의 주소 값이다. 메모리의 주소 값을 곱하거나, 나누거나, 더하거나 하는 행위는 어떠한 의미도 찾을 수 없다. 하지만 포인터와 상수의 덧셈은 가능하다. 왜냐하면 메모리 주소에서 한 칸 건너뛴 메모리 주소의 지시 값을 출력하는 방식은 활용 가치가 있기 때문이다. 이러한 측면에서 뺄셈은 포인터와 상수, 포인터와 포인터 연산 둘 다 활용할 수 있다.
포인터 간 연산 시, 반드시 자료형이 동일해야 한다. 또한 포인터에 1을 더하거나 빼는 것은 자료형의 크기 만큼 이동한다는 의미이다.
void 포인터는 이동해야 하는 범위를 알 수 없기 때문에 포인터 연산을 할 수 없다.
- e.g. 상수 + 포인터
#include <stdio.h>
int main(void)
{
char *p = "abcde";
int i = 0;
while (p[i] != 0){
printf("p + %d = %c\n", i, *(p + i));
++i;
}
}
p + 0 = a
p + 1 = b
p + 2 = c
p + 3 = d
p + 4 = e
Program ended with exit code: 0
- e.g. 포인터 - 포인터
#include <stdio.h>
int main(void)
{
int *p1;
int *p2;
char *p3;
printf("&p1 = %p\n", &p1);
printf("&p2 = %p\n", &p2);
printf("&p1 - &p2 = %ld\n", &p1 - &p2);
// printf("p2 - p3 = %p\n", &p2 - &p3);
// 'int **' and 'char **' are not pointers to compatible types
}
p1 = 0x7ffeefbff3f8
p2 = 0x7ffeefbff3f0
p1 - p2 = 1
Program ended with exit code: 0
그렇다면 왜 &p1 - &p2의 결괏값이 8이 아니라 1일까?
0x7ffeefbff3f8
-0x7ffeefbff3f0
LP64에서 Pointer는 8bytes로 정의하고 있기 때문에 8bytes의 차이를 1로 인식하는 것이다.
14.5 NULL Pointer
NULL 값이 들어있는, 즉 아무것도 가리키지 않는 포인터를 의미한다. 가리키는 것이 없기 때문에 역참조가 불가능하다. 만약 역참조를 하면 오류를 초래할 수 있다. NULL 포인터는 포인터의 NULL 여부를 확인한 후 NULL일 경우 메모리를 할당하는 방식으로 사용한다.
한편, NULL 포인터와 초기화하지 않은 포인터는 다르다. Null 포인터는 메모리를 가리키지 않는다. 하지만 초기화하지 않은 포인터는 메모리를 가리킬 수 있고, 참조할 수 있다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int* p = NULL;
printf("%p\n", p);
if (p == NULL) // if (!p)
p = malloc(sizeof(int));
printf("%p\n", p);
free(p);
return 0;
}
0x0
0x100636cc0
Program ended with exit code: 0
NULL과 ASCII NUL은 서로 다른 의미다. 따라서 같은 0이라도 그 의미를 구분해야 한다. int* p = 0은 int* p = NULL과 같은 의미다. 반면 *p = 0은 ASCII 문자의 ‘\0’(정수 0)을 의미한다.
14.6. Pointer type casting
인텔과 AMD CPU는 리틀 엔디안 방식을 사용하기 때문에 형 축소를 하게되면 오른쪽 값부터 출력됨을 주의해야 한다. 반면 형 확장을 하게 되면 함수로 할당하지 않은 공간까지 읽어오게 되므로, 쓰레기 값이 포함되어 있을 수 있다는 사실을 인지해야 한다.
- e.g.1 포인터 형 축소
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int* ip = malloc(sizeof(int));
char* cp;
*ip = 0x12345678;
cp = (char*)ip;
printf("0x%x\n", *cp);
printf("0x%x\n", *(char*)ip);
free(ip);
return 0;
}
0x78
0x78
Program ended with exit code: 0
- e.g.2 포인터 형 확장
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int* ip;
char* cp = malloc(sizeof(char));
*cp = 0x12;
ip = (int*)cp;
printf("0x%x\n", *ip);
free(cp);
return 0;
}
0x12
Program ended with exit code: 0
14.7. 포인터와 관련된 데이터 타입
-
- size_t
- 임의의 객체가 가질 수 있는 최대 크기를 의미한다. 즉 LP32에서는 size_t는 32bits이고, LP64에서 size_t는 64bits를 의미한다.
- size_t 타입의 선언은 구현 방법에 따라 정의된 행동(Implementation-defined behavior)이며, stdio.h, stdlib.h를 선언해 사용할 수 있다.
- size_t는 unsigned 즉 부호가 없는 정수다. 따라서 양의 정수를 할당해야 한다.
- 일반적인 헤더 파일 내에서 size_t의 정의
#ifndef __SIZE_T #define __SIZE_T typedef unsigned int size_t; #endif - Visual Studio에서 size_t 정의
#ifdef _WIN64 typedef unsigned __int64 size_t; #else typedef unsigned int size_t; #endif
- 일반적인 헤더 파일 내에서 size_t의 정의
-
ptrdiff_t
-
- intptr_r
- 포인터를 저장하는데 사용하며, 포인터를 정수 표현으로 바꿀 때 유용하다.
-
- uintptr_t
- unsigned intptr_r
—
15. 배열과 포인터
배열의 이름은 배열의 첫 번째 원소의 데이터 주소값을 의미한다. 그러나, 배열과 포인터는 다르다. sizeof로 포인터의 크기를 출력하면 32비트 프로세서에서는 4바이트, 64비트 프로세서에서는 8바이트의 결괏값이 나온다. 즉 프로세서에서 사용되는 포인터의 크기를 출력한다. 반대로 sizeof로 배열의 크기를 출력하면 자료형 bytes * 배열 사이즈 만큼의 결괏값을 출력한다. 즉 해당 배열이 사용하고 있는 메모리 크기를 출력한다. 다시말해 배열의 이름은 배열 전체를 의미한다.
그렇다면 왜 배열의 이름이 포인터 값을 출력할까? 그 이유는 일반적으로 배열의 이름을 포인터로 암시적 형 변환(Implicit Type Conversion)을 해주기 때문이다. 예외적으로 sizeof와 &로 주소값을 지시할 때 문자 배열을 선언하면서 문자열로 초기화할 때만 배열의 이름이 배열 그 자체를 의미한다. 그 외의 경우에서 배열은 포인터로 반환되므로 배열이 포인터로 퇴화(Decay)한다고 표현한다.
그리고 이렇게 약속한 계기는 B언어에서 C언어로 넘어오며 호환성을 확보하기 위해서였다. B언어에서는 배열의 이름에 포인터 값을 할당해 배열의 첫 번째 원소의 메모리 주소값과 별도로 배열 자체의 주소값을 가졌었다. 즉 &arr은 배열을 가리키는 포인터를, arr는 arr + 0, 즉 arr[0]을 가리키는 포인터를 의미했다. 다시말해 &arr와 arr[0]의 포인터 값이 달랐다.
그러나 C언어로 넘어오면서 메모리 사용의 효율성을 높이기 위해(즉 8bytes 하나를 줄이기 위해) 배열의 이름에 메모리 주소값을 할당하지 않았다. 그런데 C언어로 넘어가는 시기에 B언어와 원활한 통합을 위해 배열 자체의 주소값은 없지만, 포인터를 활용할 수 있도록 암시적 형 변환을 통해 배열의 이름을 배열의 첫 번째 원소의 메모리 주소 값으로 설정했다.
참고자료1
- e.g.1
#include <stdio.h>
int main(void)
{
int arr[5] = {1, 2, 3, 4, 5};
int* p;
printf("sizeof(arr) = %d\n", sizeof(arr));
printf("sizeof(p) = %d\n", sizeof(p));
printf("\n");
printf("%p\n", &arr);
printf("%p\n", &arr[0]);
printf("%p\n", arr);
return 0;
}
sizeof(arr) = 20
sizeof(p) = 8
0x7ffeefbff3e0
0x7ffeefbff3e0
0x7ffeefbff3e0
Program ended with exit code: 0
- e.g.2 Array != Pointer
#include <stdio.h>
int main(void)
{
int arr[5] = {1, 2, 3, 4, 5};
int *p;
printf("arr = %p\n", arr);
printf("arr + 1 = %p\n", arr + 1);
printf("&arr[0] + 1 = %p\n", &arr[0] + 1);
printf("&*(arr + 0) + 1 = %p\n", &*(arr + 0) + 1);
printf("*(arr + 1) = %d\n", *(arr + 1));
printf("\n");
printf("&arr = %p\n", &arr);
printf("&arr[4] = %p\n", &arr[4]);
printf("&arr + 1 = %p\n", &arr + 1);
printf("&arr + 2 = %p\n", &arr + 2);
// 5678 9abc def0 1234 5678
printf("&arr + 3 = %p\n", &arr + 3);
// 9abc def0 1234 5678 9abc
printf("\n");
printf("sizeof(arr) = %d\n", sizeof(arr));
printf("\n");
printf("&p = %p\n", &p);
printf("&p + 1 = %p\n", &p + 1);
return 0;
}
arr = 0x7ffeefbff3e0
arr + 1 = 0x7ffeefbff3e4
&arr[0] + 1 = 0x7ffeefbff3e4
&*(arr + 0) + 1 = 0x7ffeefbff3e4
*(arr + 1) = 2
&arr = 0x7ffeefbff3e0
&arr[4] = 0x7ffeefbff3f0
&arr + 1 = 0x7ffeefbff3f4
&arr + 2 = 0x7ffeefbff408
&arr + 3 = 0x7ffeefbff41c
sizeof(arr) = 20;
&p = 0x7ffeefbff3d0
&p + 1 = 0x7ffeefbff3d8
Program ended with exit code: 0
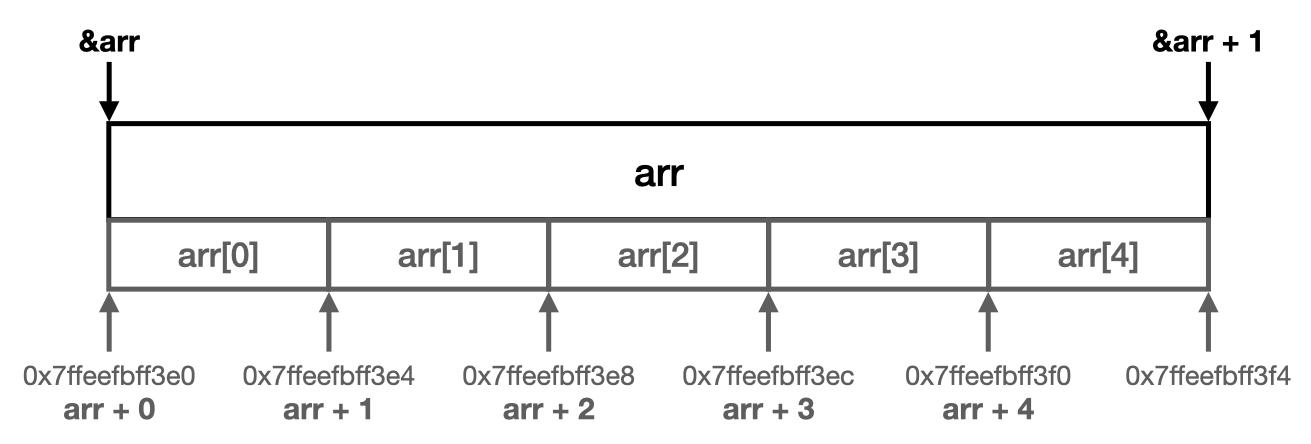
여기서 주목할 부분은 &arr + 1이다. &arr은 배열의 첫 번째 원소의 주소값이다. 즉 &arr과 arr의 결괏값은 동일하다. 그런데 arr + 1과 &arr + 1의 결괏값은 다르다. 우선 &arr + 2를 보자 &arr + 1과 20bytes 차이가 난다. &arr + 3를 보자 &arr + 2과 20bytes 차이가 난다. 이제 sizeof(arr)를 보자 20bytes이다. 즉 &arr에서 1을 더하는 행위는 sizeof(arr)의 만큼의 크기를 이동한다. 마치 &p에 1을 더하는 연산과 같다. 왜냐하면 &arr는 sizeof(arr)만큼의 크기를 가리키는 배열의 포인터기 때문이다. 따라서 &arr + 1 은 arr + sizeof(arr)/sizeof(int)와 같다.
반면 arr + 1은 &*(arr + 0) + 1(= &arr[0] + 1을 의미한다. 즉 arr의 첫 번째 원소의 주소값에서 sizeof(int)만큼을 이동한다. 즉 &arr는 배열을 가리키는 포인터고 arr는 암시적 형변환을 통해 배열의 첫 번째 원소를 가리키는 포인터다.
참고자료1
- e.g.3 포인터에 배열 할당하기
#include <stdio.h>
int main(void)
{
int arr[5] = {1, 2, 3, 4, 5};
int* p;
p = arr;
// p = arr + 0
for (int i = 0; i < 5; ++i){
printf("*(p + %d) = %d\n", i, *(p + i));
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("p + %d = %p\n", i, p + i);
}
printf("\n");
for (int i = 0; i < 5; ++i){
printf("arr[%i] = %p\n", i, &arr[i]);
}
}
*(p + 0) = 1
*(p + 1) = 2
*(p + 2) = 3
*(p + 3) = 4
*(p + 4) = 5
p + 0 = 0x7ffeefbff3e0
p + 1 = 0x7ffeefbff3e4
p + 2 = 0x7ffeefbff3e8
p + 3 = 0x7ffeefbff3ec
p + 4 = 0x7ffeefbff3f0
arr[0] = 0x7ffeefbff3e0
arr[1] = 0x7ffeefbff3e4
arr[2] = 0x7ffeefbff3e8
arr[3] = 0x7ffeefbff3ec
arr[4] = 0x7ffeefbff3f0
Program ended with exit code: 0
int arr[5]인 배열에서 유효한 인덱스 0에서 4 사이의 값을 넘어서는 범위를 인덱스로 사용했을 때(즉 배열의 범위를 벗어난 경우)의 동작은 정의되지 않았다. 따라서 예측할 수 없는 결괏값이 나온다.
- e.g.4
#include <stdio.h>
int main(void)
{
int arr[4] = {0, };
printf("arr[3] = %d\n", arr[3]);
printf("arr[4] = %d\n", arr[4]);
printf("arr[5] = %d\n", arr[5]);
return 0;
}
arr[3] = 0
arr[4] = -272632824
arr[5] = 32766
Program ended with exit code: 0
배열과 포인터는 연산이 다르다. ++p는 p = p + 1을 의미한다. 따라서 p에 초기화된 값에서 자료형 만큼 이동한다. 반대로 arr는 단순히 배열의 첫 번째 원소의 메모리 주소값일 뿐이다. 따라서 메모리 주소값 + 1을 하게 되면 1이 얼만큼인지 알 수 없기 때문에 오류가 발생한다.
- e.g.5
#include <stdio.h>
int main(void)
{
int arr[3] = {3, 4, 5};
int* p = arr;
printf("arr = %p\n", arr);
// printf("++arr = %p", ++arr);
// error: cannot increment value of type 'int [3]'
printf("p = %p\n", p);
printf("++p = %p\n", ++p);
return 0;
}
arr = 0x7ffe2252bc04
p = 0x7ffe2252bc04
++p = 0x7ffe2252bc08
Program ended with exit code: 0
arr[Y]는 *(arr + Y)로 해석된다. 즉 arr의 첫 번째 원소의 메모리 주소값에서 자료형의 크기 * Y 만큼 이동한 후 역참조하는 것을 의미한다. 따라서 컴퓨터는 arr[Y]와 Y[arr]를 동일하게 인식한다. 그러나 이는 가독성에 좋지 않기 때문에 알고만 있도록 하자.
#include <stdio.h>
int main(void)
{
int arr[5] = {1, 2, 3, 4, 5};
printf("arr[3] = %d\n", arr[3]);
printf("3[arr] = %d\n", 3[arr]);
return 0;
}
arr[3] = 4
3[arr] = 4
Program ended with exit code: 0
15.1. 2차원 배열과 포인터
int arr[]에서 arr와 &arr[0]이 다르듯 2차원 배열 int arr[][]에서 arr[0]과 &arr[0][0]은 다르다. 이차원 배열에서 arr은 arr[0]을 가리킨다. 반면 arr[0]은 arr[0][0]을 가리킨다. 메모리 주소값은 동일하지만 arr는 행을 크기로 하는 반면, arr[0]은 int형 원소 하나의 크기를 가진다.
- e.g.1 arr != arr[0]
#include <stdio.h>
int main(void)
{
int arr[3][4];
printf("arr = %p\n", arr);
printf("arr + 1 = %p\n\n", arr + 1);
printf("arr[0] = %p\n", arr[0]);
printf("arr[0] + 1 = %p\n\n", arr[0] + 1);
printf("sizeof(arr) = %d\n", sizeof(arr));
printf("sizeof(arr[0]) = %d\n", sizeof(arr[0]));
return 0;
}
arr = 0x7ffeefbff410
arr + 1 = 0x7ffeefbff420
arr[0] = 0x7ffeefbff410
arr[0] + 1 = 0x7ffeefbff414
sizeof(arr) = 48
sizeof(arr[0]) = 16
Program ended with exit code: 0
- e.g.2 sizeof(arr) & sizeof(&arr)
arr와 arr[Y] 그리고 arr[Y][X]의 값은 각각 점유하고 있는 사이즈를 나타낸다. 반면 sizeof(&arr)는 무조건 메모리 주소값을 반환하므로 포인터 크기인 8bytes(LP64)를 반환하는 것이다.
#include <stdio.h>
int main(void)
{
int arr[3][4];
printf("sizeof(arr) = %d\n", sizeof(arr));
printf("sizeof(arr[0]) = %d\n", sizeof(arr[0]));
printf("sizeof(arr[3]) = %d\n", sizeof(arr[3]));
printf("sizeof(arr[0][0]) = %d\n\n", sizeof(arr[3][4]));
printf("sizeof(&arr) = %d\n", sizeof(&arr));
printf("sizeof(&arr[3]) = %d\n", sizeof(&arr[3]));
printf("sizeof(&arr[3][4]) = %d\n", sizeof(&arr[3][4]));
printf("&arr = %p\n", &arr);
return 0;
}
sizeof(arr) = 48
sizeof(arr[0]) = 16
sizeof(arr[3]) = 16
sizeof(arr[0][0]) = 4
sizeof(&arr) = 8
sizeof(&arr[3]) = 8
sizeof(&arr[3][4]) = 8
&arr = 0x7ffeefbff410
Program ended with exit code: 0
15.2. Pointer Array
포인터 자료형을 가지는 배열이다. int* arr[3]은 int* 자료형을 가지는 크기 3(3 * sizeof(int*) bytes)의 배열을 의미한다.
#include <stdio.h>
int main(void)
{
int* arr[4];
int a = 1, b = 2, c = 3, d = 4;
arr[0] = &a;
arr[1] = &b;
arr[2] = &c;
arr[3] = &d;
// 포인터를 담는 배열이기 때문에 주소값을 할당한다.
for (int i = 0; i < 4; ++i){
printf("*arr[i] = %d\n", *arr[i]);
printf(" arr[i] = %p\n", arr[i]);
}
printf("sizeof(int*) = %d\n", sizeof(int*));
}
*arr[i] = 1
arr[i] = 0x7ffeefbff418
*arr[i] = 2
arr[i] = 0x7ffeefbff414
*arr[i] = 3
arr[i] = 0x7ffeefbff410
*arr[i] = 4
arr[i] = 0x7ffeefbff40c
sizeof(int*) = 8
Program ended with exit code: 0
15.3. Array Pointer
2차원 배열은 이중 포인터가 아니다. 단순히 y * x만큼의 메모리 주소값을 가지는 배열이다. 그러나 단일 포인터로 표현할 수도 없다. 따라서 포인터에 배열을 할당하기 위해서는 int (*p)[3]과 같은 방식의 선언이 필요하다. int (*p)[3]은 크기가 3인 배열을 가리키는 포인터다. 반면 int *p[3]은 Pointer Array에서 언급했듯이 포인터를 담는 배열이다. 이러한 차이는 연산자 우선순위에 의해 발생한다. () > [] > * 순서로 연산자를 인식한다. 따라서 int (*p)[3]는 int *p를 인식한 후 [3]을 인식한다. 반대로 int *p[3]은 p[3]을 인식한 후 int *를 인식한다.
그런데 이 때 2차원 배열의 포인터를 선언할 때 열(X)의 크기를 명시한다. 그 이유는 인덱스 계산을 위해서다.
우선 int arr[5]과 같은 배열에서 arr[3]의 메모리 주소값을 계산해보자. 이때 시작 메모리 주소값(arr)은 p라고 하고, 바이트 단위로 연산한다. 그러면 arr[3]의 메모리 주소값은 p + 3 * sizeof(int)로 계산할 수 있다. 즉 arr[y]은 p + (y * sizeof(int))로 계산할 수 있다.
이번에는 int arr[3][4]일 때 arr[2][3]을 계산해보자. 조건은 동일하다. 우선 한 행의 길이 즉 열의 갯수를 알아야 한다. 한 행은 4 * sizeof(int)만큼의 메모리를 점유하고 있다. 따라서 arr[2]의 첫 번재 포인터는 2 * 4 * sizeof(int) 값이다. 그리고 arr[y][3]의 값은 행의 y행의 메모리 주소값에서 x * sizeof(int)를 더하면 된다. 즉 int arr[Y][X] 배열에서 arr[y][x]의 메모리 주소값은 y * X * sizeof(int) + x * sizeof(int)다.
자, 도출한 arr[y][x]의 메모리 주소값 계산 공식을 보자. sizeof(int)(yX + x)를 계산하기 위해서 우리는 반드시 X를 알아야 한다. 따라서 이차원 배열을 가리키는 포인터를 선언할 때 X(열)에 대한 정보를 추가하는 것이다. 만약 열의 크기를 선언하지 않는다면, 즉 int (*p)는 arr[1][1]을 계산할 수 없다. 왜냐하면 얼만큼의 열을 연산해야 다음 행으로 가는지 알 수 없기 때문이다.

- e.g.1
#include <stdio.h>
int main(void)
{
int arr[3][4] = {0, };
int (*p)[4];
int n;
n = 1;
for (int y = 0; y < 3; ++y){
for (int x = 0; x < 4; ++x){
arr[y][x] = n++;
}
}
p = arr;
for (int y = 0; y < 3; ++y){
for (int x = 0; x < 4; ++x){
printf("p[%d][%d] = %d\n", y, x, p[y][x]);
// printf("p[%d][%d] = %d\n", y, x, *(*(p + y) + x));
}
}
return 0;
}
p[0][0] = 1
p[0][1] = 2
p[0][2] = 3
p[0][3] = 4
p[1][0] = 5
p[1][1] = 6
p[1][2] = 7
p[1][3] = 8
p[2][0] = 9
p[2][1] = 10
p[2][2] = 11
p[2][3] = 12
Program ended with exit code: 0
15.4. 이차원 배열와 이중 포인터
2차원 배열과 이중 포인터는 다르다. 2차원 배열은 일직선 상의 메모리 주소값을 가진다. 반면 이중 포인터는 행을 가리키는 포인터가 연속적이지 않고 분절되어 있다. 아래 그림에서 붙어있는 상자는 서로 연속된 메모리 주소값을 의미하고, 떨어져있는 상자는 분절된 메모리 주소값을 의미한다.

- e.g.1
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int** arr;
// printf("%p\n", arr);
// Variable 'arr' is uninitialized when used here
arr = (int**)malloc(sizeof(int) * 3);
printf("arr = %p\n", arr);
for (int i = 0; i < 4; ++i){
*(arr + i) = (int*)malloc(sizeof(int) * 4);
}
for (int y = 0; y < 3; ++y){
printf("arr[%d] = %p\n", y, arr[y]);
for (int x = 0; x < 4; ++x){
printf("arr[%d][%d] = %p\n", y, x, &arr[y][x]);
}
printf("\n");
}
arr[1][2] = 10;
printf("*(*(arr + 1) + 2) = %d\n", *(*(arr + 1) + 2));
printf("*(arr + 1) = %p\n", *(arr + 1));
printf("(arr + 1) = %p\n", (arr + 1));
printf("arr = %p\n\n", arr);
printf("sizeof(arr[0][0]) = %d\n", sizeof(arr[0][0]));
printf("sizeof(arr[0]) = %d\n", sizeof(arr[0]));
printf("sizeof(arr) = %d\n", sizeof(arr));
for (int i = 0; i < 4; ++i){
free(*(arr + i));
}
free(arr);
return 0;
}
arr = 0x100562c40
arr[0] = 0x1005613a0
arr[0][0] = 0x1005613a0
arr[0][1] = 0x1005613a4
arr[0][2] = 0x1005613a8
arr[0][3] = 0x1005613ac
arr[1] = 0x100562910
arr[1][0] = 0x100562910
arr[1][1] = 0x100562914
arr[1][2] = 0x100562918
arr[1][3] = 0x10056291c
arr[2] = 0x10055cb50
arr[2][0] = 0x10055cb50
arr[2][1] = 0x10055cb54
arr[2][2] = 0x10055cb58
arr[2][3] = 0x10055cb5c
((arr + 1) + 2) = 10
*(arr + 1) = 0x100562910
(arr + 1) = 0x100562c48
arr = 0x100562c40
sizeof(arr[0][0]) = 4
sizeof(arr[0]) = 8
sizeof(arr) = 8
Program ended with exit code: 0
16. Function(함수)
<return data type> <fuction name> (<parameters data type> <parameters> … )
{
$\quad$declarations | statements
$\quad$ return ;
}
함수의 ‘return 값의 자료형’과 함수 선언 시의 ‘return data type’이 같아야 한다.
- return 값이 없는 함수
void <fuction name> (<parameters data type> <parameters> … )
{
$\quad$ declarations | statements;
}
- Parmeter 값이 없는 함수
<return data type> <fuction name> (void)
{
$\quad$ declarations | statements
$\quad$ return ;
}
-
- 지역변수
- 함수 내에서 선언된 변수로, 함수가 끝나면 사라진다.
#include <stdio.h>
//Function Declaration(함수 선언)
void hello(void); // Function Prototype(함수 원형)
int main(void)
{
hello(void);
return 0;
}
// Function Definition(함수 정의)
void hello(void) // Function Header
{
printf("Hello, World!\n"); // Function Body
}
16.1. 매개변수(Parameters)
함수의 인자는 여러 이름으로 불린다.
함수를 선언하거나 정의할 때 함수의 인자는 ‘매개변수’ ‘Parameter’, ‘인자’, ‘Formal parameter’ 등으로 불린다.
함수를 호출할 때 함수의 인자는 ‘인수’, ‘전달인자’, ‘Argument’, ‘Actual argument’ 등으로 불린다.
16.2. main
int main(int argc, const char * argv[])
-
- argc
- argument count
-
- argv
- argument vector
- argv[0]은 실행 파일 이름으로 실행했을 경우 확장자를 포함한 실행 파일 이름을 저장하고, 싱행 파일 경로로 싱행했다면 실행 파일 경로를 저장한다.
- 공백으로 각각의 문자열을 구분하여 배열에 순서대로 저장하고, ““를 사용해 공백을 포함한 문자열을 저장할 수 있다.
16.1. 함수와 포인터
<return data type>* <fuction name> (<parameters data type>* <parameters> … )
지역변수를 return하면 컴파일 경고가 발생한다. 지역변수는 함수가 종료되는 시점에 사라지기 때문에 지역변수의 메모리 주소값을 역참조하면 쓰레기 값이 나올 수 있다.
16.1.1. Pointer parameter
포인터 매개변수를 사용하면 함수 안에서 바뀐 내용을 함수 외부 값에 적용할 수 있다. 이때 파라미터를 포인터 값으로 전달해야 한다. 즉 변수의 메모리 주소값을 함수의 파라미터 값으로 전달해 함수 외부에 있는 변수의 메모리 주소값에 접근하는 것이다. 함수 내에서 함수 외부의 값을 참조해 변경하는 것이기 때문에 함수가 끝나도 변경된 값이 유지되는 것이다. 반대로 그냥 일반 변수를 매개변수로 사용하면 인수는 함수 내부에서만 변경된다. 따라서 함수가 끝나면 변경된 값도 사라지게 된다.
- e.g.1 포인터 매개변수
#include <stdio.h>
void change(int *x, int *y)
{
int temp;
temp = *x;
*x = *y;
*y = temp;
}
int main(void)
{
int x, y;
x = 1;
y = 9;
printf("x = %d, y = %d\n", x, y);
change(&x, &y); // 인수를 포인터 값으로 전달해야 한다.
printf("x = %d, y = %d\n", x, y);
return 0;
}
x = 1, y = 9
x = 9, y = 1
Program ended with exit code: 0
- e.g.2 매개변수
#include <stdio.h>
void change(int x, int y)
{
int temp;
temp = x;
x = y;
y = temp;
}
int main(void)
{
int x, y;
x = 1;
y = 9;
printf("x = %d, y = %d\n", x, y);
change(&x, &y);
printf("x = %d, y = %d\n", x, y);
return 0;
}
x = 1, y = 9
x = 1, y = 9
Program ended with exit code: 0
포인터를 함수로 전달할 때는 포인터 사용 전 NULL 값인지 확인하는 것이 바람직하다. NULL 포인터가 전달되는 경우 어떤 동작도 실행되지 않으며, 사용하지 않았다면 발생했을 NULL 포인터에 의한 비정상 종료를 피할 수 있다.
- e.g.3
#include <stdio.h>
int* allocate_array(int *arr, int size, int value){
if(arr){
for(int i = 0; i < size; ++i){
arr[i] = value;
}
}
return (arr);
}
int main(void){
int* vector = (int*)malloc(5 * sizeof(int));
allocate_array(vector, 5, 45);
free(vector);
}
16.1.2 IN, OUT
사용자가 이해하기 쉽도록 함수 내부에서만 사용되는 매개변수앞에 IN을, 값이 변경되어 나오는 매개변수 앞에 OUT을 표기한다.
- e.g.
#include <stdio.h>
#define IN
#define OUT
void change(IN int x, OUT int* y)
{
int temp;
temp = x;
x = *y;
*y = temp;
printf("in change: x = %d, y = %d\n", x, *y);
}
int main(void)
{
int x, y;
x = 1;
y = 9;
printf("x = %d, y = %d\n", x, y);
change(x, &y); // 인수를 포인터 값으로 전달해야 한다.
printf("x = %d, y = %d\n", x, y);
return 0;
}
x = 1, y = 9
in change: x = 9, y = 1
x = 1, y = 1
Program ended with exit code: 0
16.2 함수와 배열
- 일차원 배열
<return data type> <fuction name> (<parameters data type> <parameters>[] … )
<return data type> <fuction name> (<parameters data type>* <parameters> … )
- 복합리터럴
#include <stdio.h>
void array(int arr[])
{
}
int main(void)
{
array((int[]) {1, 2, 3, 4});
return 0;
}
- 이차원 배열
<return data type> <fuction name> (<parameters data type> <parameters>[][x] … )
<return data type> <fuction name> (<parameters data type>* <parameters>[x] … )
- 복합리터럴
#include <stdio.h>
void array(int arr[][x])
{
}
int main(void)
{
array((int[3][4]) { {1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12} });
return 0;
}
17. 동적 메모리 할당(Dynamic memory allocation)
프로그램 실행 중(Run time)에 필요한 공간을 할당하는 것이다. 동적 메모리 할당의 반대인 정적 메모리 할당(Static memory allocation)은 변수 선언에 앞서 자료형을 정희해 변수의 크기를 할당하는 것처럼 프로그램 작성 시점(Compile time, Design time)에 메모리를 할당하는 것이다.
예컨대 사용자한테 입력받은 값을 모두 더하는 프로그램이 있다고 가정하자. 정적 메모리를 할당하는 경우 사용자가 입력할 것으로 예상되는 최대 범위를 미리 설정해야 하기 때문에 충분한 메모리 공간을 선제적으로 확보해야 한다. 반면 동적 메모리를 할당하는 경우 사용자가 입력한 값에 맞춰 데이터 공간을 할당하면 되므로, 동적 메모리 할당을 활용하면 메모리의 낭비를 줄일 수 있다.
즉 동적 메모리 할당을 사용하면 상수로 선언해야 했기 때문에 정적 메모리 할당밖에 할 수 없었던 배열의 사이즈를 동적 메모리 할당을 활용해 사용자 입력 값에 따라 바꿀 수 있다.
참고자료1
참고자료2
참고자료3
17.1. malloc
void* malloc(size_t size);
memory allocation, stdlib.h 헤더에 정의된 함수로 포인터에 size 만큼의 메모리 공간을 할당한다. 이때 size는 bytes단위로 지정한다. 성공하면 메모리 주소를 반환하며, 실패하면 NULL을 반환한다. 항상 void*(void pointer) 이기 때문에 Type casting이 필요하다.
주의할 점은 malloc 함수는 반드시 free 함수를 사용해 할당한 메모리를 삭제해야 한다. 메모리를 할당한 후 해제하지 않으면 프로그램이 종료된 이후에도 계속해서 메모리를 사용하기 때문에 Memory leak(누수)현상이 발생하며 낭비가 발생한다. 반대로 정적 메모리 할당에서는 프로그램의 종료 직전에 compiler가 할당된 메모리를 삭제한다.
당연하겠지만, malloc은 음수를 사용할 수 없다. 만약 크기를 음수로 설정하면 NULL을 반환한다.
malloc 함수는 메모리를 할당 할 수 없을 때 NULL을 반환한다. 따라서 사용하기 전 값을 검사하는 것이 보다 안전하다.
- e.g.
int* arr = (int*)malloc(5 * sizeof(int));
if (arr == NULL){
printr("Error");
}
else{
...
}
-
- size_t
- C99 표준에서 정의된 자료형으로, 시스템(compiler)에서 이론상 가능한 최대 크기의 unsigned 자료형을 의미한다. 즉 64비트 컴파일러에서 size_t는 8bytes로 정의한다.
- size_t can store the maximum size of a theoretically possible object of any type
- e.g.1
#include <stdio.h>
int main(void)
{
int* p;
p = (int*) malloc(sizeof(int));
if (p){
*p = 9;
printf("%d\n", *p);
printf("%p\n", p);
}
else{
printf("Error");
}
free(p);
p = NULL;
return 0;
}
9
0x100564680
Program ended with exit code: 0
-
- Dangling Pointers
- 메모리를 해제했지만 여전히 그 값을 가리키고 있는 포인터를 댕글링 포인터라고 한다. 댕글링 포인터는 메모리 접근 시 예측 불가능한 동작이 발생할 가능성이 있고, 메모리에 접근할 수 없는 경우 Segmentation falut를 발생시킨다. 또한 잠재적 보안 위험을 가진다. 따라서 메모리를 해제한 뒤 해제한 메모리에 접근하려는 행동이나, 함수 호출에서 자동 변수를 가리키는 포인터를 반환하는 행동을 하지 않아야 한다. 이러한 행위는 댕글링 포인터를 유발한다.
메모리가 해제된 포인터를 역참조하는 경우에 대한 정의는 없다(undefined). 따라서 해제된 포인터를 NULL로 초기화해 댕글링 포인터와 같은 의도치 않은 에러를 제한할 수 있다. 그러나, 처음 초기화할 때를 제외하고는 상수 포인터에 NULL을 할당할 수 없다. 따라서 권장되는 방법은 아니다.
17.2 free
void free(void *ptr);
malloc으로 Heap영역에 확보한 메모리 저장 공간은 반드시 free로 해제해야 Memory leak(누수)가 발생하지 않는다. 또한 할당한 순서의 반대로 free를 해야 오류가 발생하지 않는다. 예컨대 이차원 포인터에서 arr[0]을 arr[0][0]보다 먼저 free를 하게 되면 오류가 발생할 수 있다.
test(26053,0x1000ebe00) malloc: *** error for object 0x100708ed0: pointer being freed was not allocated
test(26053,0x1000ebe00) malloc: *** set a breakpoint in malloc_error_break to debug
double free(이중 해제)가 일어나면 보안 문제가 발생할 수 있다. 따라서 메모리를 해제한 후 포인터에 NULL을 할당하는 습관을 들이는 것이 좋다. NULL 포인터를 해제하려고 하면 대부분의 힙 관리자는 해제 시도를 무시한다.
char* str = (char*)malloc(sizeof(char) * 5);
...
free(str);
str = NULL;
17.3. realloc
void* realloc(void* ptr, size_t size)
재할당된 메모리 영역의 포인터를 반환한다. 첫 번째 인자는 앞서 할당한 포인터이고, 두 번째 인자는 할당할 메모리 크기다. 새로 할당할 메모리 크기가 할당했던 메모리 크기보다 작은 경우 나머지 메모리는 heap으로 반환된다. 그러나, 반환된 메모리는 초기화되지 않을 수 있다. 반대로 할당할 메모리 크기가 할당했던 메모리 크기보다 큰 경우 연속된 메모리 주소값을 할당한다. 그러나, 연속된 메모리 주소값이 이미 사용 중에 있어 할당할 수 없는 경우, heap의 다른 메모리 영역에 기존 내용을 복사한다. ptr이 NULL이 아니고 size가 0이면 앞서 할당했던 포인터를 해제한다.
17.4. alloca
Stack 영역의 메모리를 할당한다.(MS Winodws에서는 malloca와 동일하다.) 따라서 시스템이 Stack 기반이 아니면 작동이 원활하지 않을 수 있다. 때문에 C 표준 함수가 아니다.
17.3. 2차원 배열의 동적 할당
17.3.1. 불연속 메모리 할당
2차원 배열과 다르게 불연속한 메모리 주소값을 할당하는 방법이다.
- e.g. arr[3][4]
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int** pad;
int n = 1;
pad = (int**)malloc(sizeof(int*) * 3);
for (int i = 0; i < 3; ++i){
printf("pad + %d = %p\n", i, pad + i);
}
for (int i = 0; i < 4; ++i){
*(pad + i) = (int*)malloc(sizeof(int) * 4);
printf("pad[%d] = %p\n", i, *(pad + i));
}
for (int y = 0; y < 3; ++y){
for (int x = 0; x < 4; ++x){
*(*(pad + y) + x) = n++;
printf("pad[%d][%d] = %d\n", y, x, pad[y][x]);
}
}
for (int i = 0; i < 4; ++i){
free(pad[i]);
}
free(pad);
return 0;
}
pad + 0 = 0x10065acf0
pad + 1 = 0x10065acf8
pad + 2 = 0x10065ad00
pad[0] = 0x100640af0
pad[1] = 0x1006425a0
pad[2] = 0x100640d90
pad[3] = 0x10063f740
pad[0][0] = 1
pad[0][1] = 2
pad[0][2] = 3
pad[0][3] = 4
pad[1][0] = 5
pad[1][1] = 6
pad[1][2] = 7
pad[1][3] = 8
pad[2][0] = 9
pad[2][1] = 10
pad[2][2] = 11
pad[2][3] = 12
Program ended with exit code: 0
17.3.2. 인접한 메모리 할당
2차원 배열처럼 연속한 메모리 주소값을 할당하는 방법이다.
- e.g. arr[3][4] to Double pointer
.png "연속 2차원 포인터")
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int** pad;
int n = 1;
pad = (int**)malloc(sizeof(int*) * 3);
for (int i = 0; i < 3; ++i){
printf("pad + %d = %p\n", i, pad + i);
}
*(pad + 0) = (int*)malloc(sizeof(int) * 3 * 4);
for (int i = 0; i < 3; ++i){
*(pad + i) = *(pad + 0) + (i * 4);
printf("pad[%d] = %p\n", i, *(pad + i));
}
for (int y = 0; y < 3; ++y){
for (int x = 0; x < 4; ++x){
*(*(pad + y) + x) = n++;
printf("pad[%d][%d] = %d\n", y, x, pad[y][x]);
}
}
free(pad[0]);
free(pad);
return 0;
}
pad + 0 = 0x1005599b0
pad + 1 = 0x1005599b8
pad + 2 = 0x1005599c0
pad[0] = 0x1005599d0
pad[1] = 0x1005599e0
pad[2] = 0x1005599f0
pad[0][0] = 1
pad[0][1] = 2
pad[0][2] = 3
pad[0][3] = 4
pad[1][0] = 5
pad[1][1] = 6
pad[1][2] = 7
pad[1][3] = 8
pad[2][0] = 9
pad[2][1] = 10
pad[2][2] = 11
pad[2][3] = 12
Program ended with exit code: 0
- e.g. arr[3][4] to Single pointer
일차원 배열에 각각 값을 할당한다. 그러나 배열이 아니기 때문에 pa[0][0]과 같은 방법으로 참조할 수 없다. 따라서 행이 바뀌는 지점을 직접 계산해야 한다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int* pa;
int n = 1;
pa = (int*)malloc(sizeof(int) * 3 * 4);
for (int i = 0; i < (4 * 3); ++i){
printf("pad + %d = %p \n", i, pa + i);
}
for (int y = 0; y < 3; ++y){
for (int x = 0; x < 4; ++x){
*(pa + (4 * y) + x) = n++;
printf("*(pa + (4 * %d) + %d) = %d \n", y, x, *(pa + (4 * y) + x));
}
}
free(pa);
return 0;
}
pad + 0 = 0x10064de50
pad + 1 = 0x10064de54
pad + 2 = 0x10064de58
pad + 3 = 0x10064de5c
pad + 4 = 0x10064de60
pad + 5 = 0x10064de64
pad + 6 = 0x10064de68
pad + 7 = 0x10064de6c
pad + 8 = 0x10064de70
pad + 9 = 0x10064de74
pad + 10 = 0x10064de78
pad + 11 = 0x10064de7c
*(pa + (4 * 0) + 0) = 1
*(pa + (4 * 0) + 1) = 2
*(pa + (4 * 0) + 2) = 3
*(pa + (4 * 0) + 3) = 4
*(pa + (4 * 1) + 0) = 5
*(pa + (4 * 1) + 1) = 6
*(pa + (4 * 1) + 2) = 7
*(pa + (4 * 1) + 3) = 8
*(pa + (4 * 2) + 0) = 9
*(pa + (4 * 2) + 1) = 10
*(pa + (4 * 2) + 2) = 11
*(pa + (4 * 2) + 3) = 12
Program ended with exit code: 0
17.3.3. 포인터 배열을 활용한 2차원 배열 동적 할당
18. Struct(구조체)
struct <tag> {
<data type> <member1 name>;
<data type> <member2 name>;
…
};
typedef struct <tag> {
<data type> <member1 name>;
<data type> <member2 name>;
…
} <type name>;
Data strubture(자료 구조), 연관된 정보를 하나로 묶을 때 사용한다. 일반적으로 구조체는 main 함수 밖에서 정의한 후 함수 내에서 변수로 선언해서 사용한다. 만약 함수 내에서 구조체를 정의하면 해당 함수 내에서만 구조체를 사용할 수 있다. 구조체 변수에 접근할 때는 .(dot)을 사용한다. 구조체는 struct 키워드 또는 typedef 키워드를 사용해 선언할 수 있다. 관습적으로 구조체 tag 앞에서는 _(Underscore)를 붙인다.
- 구조체 선언 방법
- 구조체와 변수 각각 선언
#include <stdio.h>
#include <string.h>
struct _person {
char name[20];
char gender[11];
int age;
};
int main(void)
{
struct _person user_1;
strcpy(user_1.name, "Adam");
strcpy(user_1.gender, "Male");
user_1.age = 100;
struct _person user_2;
strcpy(user_2.name, "Eve");
strcpy(user_2.gender, "Female");
user_2.age = 100;
return 0;
}
- 구조체와 변수 동시에 선언
#include <stdio.h>
#include <string.h>
struct _person {
char name[20];
char gender[11];
int age;
} user_1;
int main(void)
{
strcpy(user_1.name, "Adam");
strcpy(user_1.gender, "Male");
user_1.age = 100;
struct _person user_2;
strcpy(user_2.name, "Eve");
strcpy(user_2.gender, "Female");
user_2.age = 100;
return 0;
}
- 구조체와 변수 각각 선언하는 동시에 초기화
member name을 명시하지 않고 쓸 경우에는 구조체 member가 선언된 순서대로 값을 할당해야 한다. 따라서 중간에 있는 member를 생략할 수 없다.
#include <stdio.h>
#include <string.h>
struct _person {
char name[20];
char gender[11];
int age;
};
int main(void)
{
struct _person user_1 = {.gender = "Male", .name = "Adam", .age = 100};
struct _person user_2 = {"Eve", "Female", 100};
return 0;
}
- typedef로 구조체의 별칭(Alias) 지정
struct tag과 struct alias는 같아도 되지만, 구분해주는 것이 가독성에 있어 더 좋다. struct alias를 사용하면 변수를 선언할 때 struct keyword를 생략할 수 있다.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct _person {
char* name;
char* gender;
int age;
} person;
int main(void)
{
person user_1;
user_1.name= (char*)malloc(sizeof(char) * (strlen("Adam") + 1));
strcpy(user_1.name, "Adam");
user_1.gender= (char*)malloc(sizeof(char) * (strlen("Male") + 1));
strcpy(user_1.gender, "Male");
user_1.age = 100;
person user_2;
user_2.name= (char*)malloc(sizeof(char) * (strlen("Eve") + 1));
strcpy(user_2.name, "Eve");
user_2.gender= (char*)malloc(sizeof(char) * (strlen("Female") + 1));
strcpy(user_2.gender, "Female");
user_2.age = 100;
free(user_1.name);
free(user_1.gender);
free(user_2.name);
free(user_2.gender);
return 0;
}
- Anonymous structure(익명 구조체)
구조체 tag를 지정하지 않고 alias만 사용한다.
typedef struct {
char* name;
char* gender;
int age;
} person;
- Person에 대한 포인터를 선언하고 메모리를 할당하는 방법 ->(point-to) 연산자 활용.
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
ptrPerson -> first_name = (char*)malloc(strlen("jenny") +1);
strcpy(ptrPerson -> first_name, "jenny");
ptrPerson -> age = 23;
- 포인터 역참조 후 .(dot) 사용
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
*(ptrPerson).first_name = (char*)malloc(strlen("jenny") +1);
strcpy(*(ptrPerson).first_name, "jenny");
*(ptrPerson).age = 23;
18.1 Struct Pointer
struct <struct tag> <pointer variable name> = malloc(sizeof(struct <struct tag*>));
포인터 변수로 선언해야 함을 잊지 말자!
- Arrow operator(->, 화살표 연산자)
user_1->name은 (*user_1).name과 동일하다. 앞서 구조체를 가리키는 포인터를 선언했다. 따라서 역참조연산자를 사용하면 구조체를 가리키게 된다. 그런데 .(dot)이 *보다 우선순위가 높기 때문에 ()를 통해 역참조를 우선 수행해야 한다.
pointer to struct _person에서 역참조를 하면 struct _person만 남는다.
- e.g.1
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct _person{
char* name;
char* gender;
int age;
} person;
int main(void)
{
person* user_1 = malloc(sizeof(struct _person));
printf("sizeof(person) = %d\n\n", sizeof(person));
// struct _person(tag) = person(alias)
printf("user_1 = %p\n", user_1);
printf("user_1 + 1 = %p\n\n", user_1 + 1);
user_1->name= (char*)malloc(sizeof(char) * (strlen("Adam") + 1));
user_1->gender= (char*)malloc(sizeof(char) * (strlen("Male") + 1));
printf("user_1->name = %p\n", user_1->name);
printf("user_1->gender = %p\n", user_1->gender);
strcpy(user_1->name, "Adam");
strcpy(user_1->gender, "Male");
user_1->age = 100;
person* user_2 = malloc(sizeof(struct _person));
user_2->name= (char*)malloc(sizeof(char) * (strlen("Eve") + 1));
strcpy(user_2->name, "Eve");
user_2->gender= (char*)malloc(sizeof(char) * (strlen("Female") + 1));
strcpy(user_2->gender, "Female");
user_2->age = 100;
free(user_1->name);
free(user_1->gender);
free(user_2->name);
free(user_2->gender);
free(user_1);
return 0;
}
sizeof(person) = 24
user_1 = 0x10074fbb0
user_1 + 1 = 0x10074fbc8
user_1->name = 0x1007359b0
user_1->gender = 0x100737460
Program ended with exit code: 0
18.2 Struct Size
C에서 구조체를 정렬할 때는 member 중 가장 크기가 큰 자료형의 배수로 정렬하고, 남는 공간을 채우는 것을 padding이라고 한다. 그런데 32bits 프로세서는 4bytes, 64bits 프로세서는 8bytes가 가장 효율적인 단위이다. 따라서 프로세서에 맞춰 4의 배수 또는 8의 배수로 구조체의 member를 정렬하는 것이 좋다. 예컨대 32bits 프로세서에서 char로만 member를 구성할 경우 의도적으로 사용하지는 않지만 int형 member를 하나 선언해준다.
-
- offsetof
- <stddef.h>
- 구조체에서 member의 위치(offset)을 반환한다.
- e.g.
#include <stdio.h>
#include <stddef.h>
typedef struct _st_1{
char c1;
char c2;
short s1;
int i1;
char c3;
char* cp1;
};
int main(void)
{
struct _st_1 st1;
printf("%d\n", sizeof(struct _st_1));
printf("%d\n", sizeof(st1));
printf("%d\n\n", sizeof(st1.c1));
printf("%d\n", offsetof(struct _st_1, c1));
printf("%d\n", offsetof(struct _st_1, c2));
printf("%d\n", offsetof(struct _st_1, s1));
printf("%d\n", offsetof(struct _st_1, i1));
printf("%d\n", offsetof(struct _st_1, c3));
printf("%d\n", offsetof(struct _st_1, cp1));
return 0;
}
24
24
1
0
1
2
4
8
16
Program ended with exit code: 0
18.3. Struct Memory
- memset으로 메모리 0으로 초기화하기
#include <stdio.h>
#include <string.h>
typedef struct _st1{
int i1;
char c3;
char* cp1;
};
int main(void)
{
struct _st1 s1;
struct _st1* s2 = malloc(sizeof(struct _st1));
memset(&s1, 0, sizeof(struct _st1));
memset(s2, 0, sizeof(struct _st1));
free(s2);
return 0;
}
- memcpy로 메모리 복사하기
#include <stdio.h>
#include <string.h>
typedef struct _st1{
int i1;
char c3;
char* cp1;
};
int main(void)
{
struct _st1 s1;
struct _st1* s2 = malloc(sizeof(struct _st1));
memcpy(s2, &s1, sizeof(struct _st1));
free(s2);
return 0;
}
18.4. Struct Array
struct <tag> <variable name>[<array size>]
- e.g.1
#include <stdio.h>
#include <string.h>
typedef struct {
char name[20];
char gender[11];
int age;
} person;
int main(void)
{
person ps[2];
strcpy(ps[0].name, "Adam");
strcpy(ps[0].gender, "Male");
ps[0].age = 100;
strcpy(ps[1].name, "Eve");
strcpy(ps[1].gender, "Female");
ps[1].age = 100;
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i].name, ps[i].gender, ps[i].age);
}
return 0;
}
Adam Male 100 Eve Female 100 Program ended with exit code: 0
- e.g.2
#include <stdio.h>
#include <string.h>
typedef struct {
char name[20];
char gender[11];
int age;
} person;
int main(void)
{
person ps[2] = { {"Adam", "Male", 100},
{"Eve", "Female", 100}
};
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i].name, ps[i].gender, ps[i].age);
}
return 0;
}
Adam Male 100 Eve Female 100 Program ended with exit code: 0
18.3. Struct Pointer Array
- e.g.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct {
char name[20];
char gender[11];
int age;
} person;
int main(void)
{
person* ps[2];
for (int i = 0; i < (sizeof(ps) / sizeof(person*)); ++i){
ps[i] = malloc(sizeof(person));
}
strcpy(ps[0]->name, "Adam");
strcpy(ps[0]->gender, "Male");
ps[0]->age = 100;
strcpy(ps[1]->name, "Eve");
strcpy(ps[1]->gender, "Female");
ps[1]->age = 100;
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i]->name, ps[i]->gender, ps[i]->age);
free(ps[i]);
}
return 0;
}
Adam Male 100 Eve Female 100 Program ended with exit code: 0
18.5. 구조체 중첩
- e.g.1
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct {
char name[20];
char gender[11];
struct _age{
int child;
int teen;
int adult;
} age;
} person;
int main(void)
{
person* ps[2];
for (int i = 0; i < (sizeof(ps) / sizeof(person*)); ++i){
ps[i] = malloc(sizeof(person));
}
strcpy(ps[0]->name, "Adam");
strcpy(ps[0]->gender, "Male");
ps[0]->age.adult = 100;
strcpy(ps[1]->name, "Eve");
strcpy(ps[1]->gender, "Female");
ps[1]->age.adult = 100;
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i]->name, ps[i]->gender, ps[i]->age.adult);
free(ps[i]);
}
return 0;
}
- e.g.2
struct _age{
int child;
int teen;
int adult;
};
typedef struct {
char name[20];
char gender[11];
struct _age age;
} person;
int main(void)
{
person* ps[2];
for (int i = 0; i < (sizeof(ps) / sizeof(person*)); ++i){
ps[i] = malloc(sizeof(person));
}
strcpy(ps[0]->name, "Adam");
strcpy(ps[0]->gender, "Male");
ps[0]->age.adult = 100;
strcpy(ps[1]->name, "Eve");
strcpy(ps[1]->gender, "Female");
ps[1]->age.adult = 100;
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i]->name, ps[i]->gender, ps[i]->age.adult);
free(ps[i]);
}
return 0;
}
19. union(공용체)
구조체가 member의 자료형 크기의 합보다 크거나 작은 크기를 가지는 반면, 공용체는 member 중 가장 큰 자료형의 크기를 가진다. 따라서 member 중 하나에 값을 할당하면 나머지 member의 값은 쓰레기 값이 출력된다. 따라서 공용체의 member는 한 번에 하나씩 써야 한다.
- e.g.
#include <stdio.h>
#include <string.h>
union person {
char name[20];
char gender[11];
int age;
};
int main(void)
{
union person ps[2];
printf("sizeof(ps) = %d\n", sizeof(ps));
printf("sizeof(union person) = %d\n\n", sizeof(union person));
strcpy(ps[0].name, "Adam");
strcpy(ps[1].gender, "Female");
for (int i = 0; i < 2; ++i){
printf("%s\n%s\n%d\n", ps[i].name, ps[i].gender, ps[i].age);
}
return 0;
}
sizeof(ps) = 40
sizeof(union person) = 20
Adam
Adam
1835099201
Female
Female
1634559302
Program ended with exit code: 0
20. Endianness(엔디언)
바이트를 배열하는 순서(Byte order)을 의미한다. 1byte는 8bits이고 16진법으로 8bits는 2글자로 표현한다. 이러한 이유로 아래 사진에서 글자 두 개씩 순서가 바뀐다.
사람이 익숙하지 않은 리틀엔디안을 방식을 사용하는 이유는 컴퓨터의 처리 속도를 위해서다. 두 수의 덧셈을 할 때 일의 자리부터 더해나간다. 그리고 각 자리수의 합이 10 이상이면 다음 자리수에 1을 더한다. 예컨대 2021 와 7979를 더할 때 우리는 아래와 같이 계산한다.
1 + 9 = 10,
10 + 20 + 70 = 100,
0 + 900 + 100 = 1,000,
1,000 + 2,000 + 7,000 = 10,000
따라서 일의 자리 수부터 메모리에 저장되는 리틀엔디안 방식이 사칙연산이 더 빠르다. 반대로 두 수를 비교할 때는 큰 자리수부터 비교하는 빅엔디안 방식이 더 빠르다. 또한 빅엔디안이 디버깅을 할 때 사람이 이해하기 편하다는 장점을 가지고 있다. 각각 장단점이 존재하기 때문에 Intel x86, AMD는 리틀엔디안 방식을, IBM은 빅엔디안 방식을 사용한다. 그런데 서로 다른 엔디안 방식을 가지고 있기 때문에 호환성 문제가 발생한다. 이를 위해 네트워크에서 데이터를 전송할 때 포맷인 network byte order를 빅엔디안 방식으로 사용하기로 합의했다.
참고자료1
참고자료2
-
Little-endian 높은 주소에서 낮은 주소로 바이트를 배열한다.

-
Big endian 낮은 주소에서 높은 주소로 바이트를 배열한다.
 —
—
21 enum(열거형)
enumeration, 열거형의 값은 첫 번째 항목만 값을 할당하면 다음 값은 자동적으로 1씩 더한 값이 할당된다. 이 때 아무 것도 할당하지 않으면 0부터 시작한다. 또한 각각 값을 따로 할당할 수도 있다.관습적으로 열거형 이름이나 값을 정의할 때 대문자만 사용한다.
값을 구분할 때 ;(Semicolon)이 아니라 ,(Comma) 임을 주의하자!
- e.g.1
#include <stdio.h>
typedef enum _WEEK{
SUNDAY = 0,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
DayOfWeekCount // 0부터 하나씩 더하기 때문에 마지막에 위치하면 항목의 개수가 된다.
} DAY_OF_WEEK;
int main(void)
{
for (DAY_OF_WEEK i = 0; i < DayOfWeekCount; ++i){
printf("%d\n", i);
}
return 0;
}
0
1
2
3
4
5
6
Program ended with exit code: 0
- e.g.2 Switch 분기문
#include <stdio.h>
typedef enum _SAMSUNG_OWNER{
FOUNDER,
_2ND_G,
_3RD_G
} OWNER;
int main(void)
{
OWNER ssow;
printf("1. Founder\n 2. 2nd generation\n 3. 3rd generation\n");
scanf("%d + 1", &ssow);
ssow = ssow - 1;
switch (ssow)
{
case FOUNDER:
printf("Byungchul Lee(1910.02.12 ~ 1987.11.19)\n");
break;
case _2ND_G:
printf("Kunhee Lee(1942.01.09 ~ 2020.10.25)\n");
break;
case _3RD_G:
printf("Jaeyong Lee(1968.06.23 ~ )\n");
break;
default:
break;
}
return 0;
}
. 기억 부류 지정자(Storage class specifier)
| Specifiers | 저장 장소 | Scope(범위) | Default initializer(초깃값) | Lifetime(수명 주기) |
|---|---|---|---|---|
| auto | Stack | Block | Uninitialized (초기화되지 않음) |
Block 시작부터 종료까지 |
| register | CPU Register | Block | Uninitialized (초기화되지 않음) |
Block 시작부터 종료까지 |
| static | 데이터 섹션(초기화) BSS 섹션(비초기화) |
Blcok or File | 0 | Program 시작부터 종료까지 |
| extern | 데이터 섹션(초기화) BSS 섹션(비초기화) |
Program | 0 | Program 시작부터 종료까지 |
.1. auto
auto <data type> <variable name>
Automatic variable(자동 변수), auto로 선언한 변수는 Block이 끝나면 사라진다. 따로 변수의 형태를 선언하지 않는 경우 자동 변수로 선언하며, auto 키워드는 생략한다.
.2. register
register <data type> <variable name>
register 변수는 메모리 대신 CPU register를 사용하기 때문에 다른 변수보다 속도가 빠르다. 따라서 반복 횟수가 매우 많을 때 유용하다. 단 CPU register의 개수가 한정되어 있기 때문에 register을 붙인 변수가 모두 CPU register를 사용하지는 않는다. 특히, CPU register를 사용하기 때문에 메모리에 저장되지 않고, 따라서 &를 활용해 메모리 주소를 구할 수 없다. 그러나 register 변수에 메모리 주소는 저장할 수 있기 때문에 역참조 연산자 *는 사용할 수 있다.
.3. static
.3.1. 정적 변수
static <return data type> <fuction name> (<parameters data type> <parameters> … )
Static variable, static으로 선언한 변수는 Program 전체에서 작동한다. 따라서 함수 밖에서도 변수가 유지된다.
다른 source file(project 내 다른 파일)에 있는 정적 변수는 전역 변수로 사용할 수 없다.
TODO: 정적변수와 전역변수 차이 상세히
정적 변수는 함수의 매개변수로 사용할 수 없다.
- e.g.
#include <stdio.h>
void sta(void)
{
static int a = 0;
int b = 0;
printf("a = %d, b = %d\n", a, b);
++a;
++b;
}
int main(void)
{
for (int i = 0; i < 10; ++i)
{
sta();
}
return 0;
}
a = 0, b = 0
a = 1, b = 0
a = 2, b = 0
a = 3, b = 0
a = 4, b = 0
a = 5, b = 0
a = 6, b = 0
a = 7, b = 0
a = 8, b = 0
a = 9, b = 0
Program ended with exit code: 0
.3.2 정적 함수
static <data type> <variable name>
한 Project 내에서는 중복된 함수 이름을 사용할 수 없다. 그러나, 정적 함수를 사용하면 각 파일 안에서만 사용할 수 있으므로, 파일마다 동일한 이름의 함수를 만들 수 있다.
.4. extern
전역변수
메모리의 종류
| 접근 범위(Scope) | 수명(Lifetime) | |
|---|---|---|
| 전역(Global) | 전체 파일 | 애플리케이션 실행이 끝날 때 |
| 정적(Static) | 변수를 선언한 함수 | 애플리케이션 실행이 끝날 때 |
| 자동(Automatic) / Local | 함수 | 함수 실행이 끝날 때 |
| 동적(Dynamic) | 참조하는 포인터 | 메모리 해제할 때 |
-
- 동적 변수
- Heap 메모리 영역에 할당된다.
- 해제(Release)하지 않으면 계속 메모리에 남아있는다.
- 포인터를 사용해 할당된 메모리 영역을 참조하고, 포인터에 의해 접근이 제한된다.
typedef
typedef <data type> <alias>
data type의 alias를 만들 수 있다.
- e.g.
typedef int* int_p;
메모리 구조
-
- Stack
- 함수 내에서 선언한 지역변수와 함수의 매개변수를 저장하는 데이터 영역이다. 함수의 사용(호출)이 끝나면 Stack 영역에서 자동으로 데이터를 제거한다.
- 스택과 힙은 같은 메모리 영역을 공유한다. 이때 스택은 메모리의 낮은 부분을 사용하고 힙은 메모리의 높은 부분을 사용하는 경향이 있다.
- Stack Frames을 포함한다.
-
- Stack Frames
- 활성화 레코드(Activation Records) 또는 활성화 프레임(Activation Frames)라고도 불리며 함수 호출 시 전달되는 매개변수와 로컬 변수를 포함한다.
- 구성 요소
-
- 반환주소
- 함수 종료 후 돌아가야할 프로그램 내의 주소
- 로컬 변수 저장소
- 매개변수 저장소
- Stack Pointer and Base Pointer
-
-
- Heap
- 동적 할당 변수(malloc 등)을 저장하는 영역으로, 사용자가 직접 관리할 수 있는 데이터 영역이다.
- Heap 영역은 free를 총해 할당된 데이터를 제거해야 한다.
- managed by malloc, calloc, realloc, and free
-
- Uninitialized data(bss) segment
- 초기화하지 않은 전역변수와 정적변수를 저장하는 데이터 영역이다.
- 전역변수와 정적변수는 별도의 초기화가 없을 때 자동으로 0의 값을 가지도록 초기화된다.
-
- Initialized data segment
- 초기화한 전역변수와 정적변수를 저장하는 데이터 영역이다.
- global or static variables
-
- Text(Code) segment
- Program source code, 상수, 문자열를 저장하는 데이터 영역이다.
- read-only and fixed size
Type qualifier(형 한정자)
| 키워드 | 설명 |
|---|---|
| const | 값을 변경할 수 없음 |
| volatile | 변수를 사용할 때 항상 메모리에 접근하도록 만듦 |
| restrict | 메모리 접근 횟수를 줄이는 최적화를 함 |
| _Atomic | 여러 스레드에서 변수를 사용할 때 변경한 값이 정확히 적용되도록 보장(원자적 연산) |
재귀호출(Recursive call)
재귀호출을 사용할 경우 반드시 종료 조건을 통해 재귀가 끝나는 부분을 설정해야 한다. 그렇지 않으면 계속 Stack이 쌓여 Srack overflow가 발생한다. 재귀함수는 반복문으로 바꿀 수 있다. 재귀함수는 재귀적 표현이 이해가 쉬운 경우, 변수 사용을 줄일 수 있는 경우 사용한다.?
-
- 스택 오버플로우(Stack overflow)
단어
-
- 의사코드(Pseudo code)
- 프로그래밍 언어가 아니라 사람의 말로 프로그래밍 언어를 표현한 것.
-
- buffer
- 문자열을 생성할 대 사용하는 배열이나 메모리 공간(포인터)
참고자료(References)
- C언어 코딩 도장
- 씹어먹는 C언어
- 모두의 C언어
- C 프로그래밍: 현대적 접근
- Understanding and Using C Pointers(C 포인터의 이해와 활용) - Richard Reese
- 김성엽의 C 언어 이야기
- Learn C Programming
- C language standard (ISO/IEC 9899:1999)
- Onsil’s blog
- 컴퓨터에서의 실수 표현: 고정소수점 vs 부동소수점
- 네이버 사전
유용한 자료
코드 공유 Site
코드 단계별 Visualization
-
auto, break, case, char, const, continue, deefualt, do, double, less, hextern, float, for, goto, if, inline, int, long, register, restrict, return, short, signed, sizeof, static, struct, switch, typedof, union, unsigned, voil, volatile, while, _Bool, _Complex, _Imaginary ↩
-
https://velog.io/@kevinkim2586/C언어-기본-자료형과-변수 ↩
댓글남기기